Research talk: Maia Chess: A human-like neural network chess engine
- Reid McIlroy-Young | University of Toronto
- Microsoft Research Summit 2021 | Reinforcement Learning
Even when machine learning surpasses human ability in a domain, there are many reasons why AI systems that capture human-like behavior would be desirable. For example, humans may want to learn and collaborate, or humans may need to interact with independent AI agents. A first step in aligning AI agents’ behavior to that of humans is creating agents that better understand human behavior. University of Toronto PhD student Reid McIlroy-Young will present his work, done in collaboration with Microsoft Research, building neural chess engines that can predict human behavior at different skill levels. Furthermore, these engines can be calibrated to target the decisions of specific players via fine-tuning. He will first discuss the value of studying the intersection of human and AI, and the results. He will also discuss where reinforcement learning was outperformed by a classification approach and conclude with a look at the benefits of having research that can be understood by a wide audience.
Learn more about the 2021 Microsoft Research Summit: https://Aka.ms/researchsummit (opens in new tab)
Reinforcement Learning
-

Opening remarks: Reinforcement Learning
- Katja Hofmann
-
-
-
-
Research talk: Evaluating human-like navigation in 3D video games
- Raluca Georgescu,
- Ida Momennejad
-
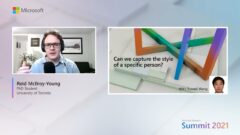
Research talk: Maia Chess: A human-like neural network chess engine
- Reid McIlroy-Young
-
Fireside chat: Opportunities and challenges in human-oriented AI
- Ashley Llorens,
- Katja Hofmann,
- Siddhartha Sen
-

Research talk: Making deep reinforcement learning industrially applicable
- Jiang Bian,
- Tie-Yan Liu
-

Panel: Generalization in reinforcement learning
- Mingfei Sun,
- Roberta Raileanu,
- Wendelin Böhmer
-

Research talk: Project Dexter: Machine learning and automatic decision-making for robotic manipulation
- Andrey Kolobov,
- Ching-An Cheng
-
-
-
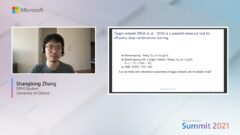
Research talk: Breaking the deadly triad with a target network
- Shangtong Zhang
-
Panel: The future of reinforcement learning
- Geoff Gordon,
- Emma Brunskill,
- Craig Boutilier
-
Closing remarks: Reinforcement Learning
- John Langford