
機器翻譯
什麼是機器翻譯?
機器翻譯系統是一種應用程式或線上服務,使用機器學習技術將大量文字翻譯成任何一種其支援的語言。該服務可將「源」文字從一種語言翻譯成不同的「目標」語言。
雖然機器翻譯技術背後的概念和使用介面相對簡單,但其背後的科學和技術卻極為複雜,並結合了多項尖端技術,尤其是深度學習(人工智慧)、大數據、語言學、雲端運算和 Web API。
自 2010 年代初,一種新的人工智慧技術 - 深度神經網路 (又稱深度學習) - 讓語音辨識技術達到一定的品質水準,讓 Microsoft Translator 團隊得以將語音辨識與核心文字翻譯技術結合,推出全新的語音翻譯技術。
歷史上,業界使用的主要機器學習技術是統計機器翻譯 (SMT)。SMT 使用先進的統計分析,根據幾個字詞的上下文,估計出一個字詞可能的最佳翻譯。自 2000 年代中期以來,包括 Microsoft 在內的所有主要翻譯服務供應商都開始使用 SMT。
神經機器翻譯 (NMT) 的出現引起了翻譯技術的徹底轉變,帶來了更高質量的翻譯。這種翻譯技術在 2000 年開始為使用者和開發人員部署。 2016 年下半年.
SMT 和 NMT 翻譯技術都有兩個共同點:
- 兩者都需要大量的前期人工翻譯內容(高達數百萬個翻譯句子)來訓練系統。
- 兩者都不像雙語字典一樣,根據可能的翻譯清單翻譯詞彙,而是根據句子中使用的詞彙的上下文進行翻譯。
什麼是 Translator?
翻譯和語音服務,隸屬於 認知服務 是微軟提供的機器翻譯服務。
文字翻譯
自 2007 年起,Microsoft 團體便開始使用 Translator,並自 2011 年起提供 API 給客戶使用。Microsoft 內部廣泛使用 Translator。它被納入產品本地化、支援和線上溝通團隊。您也可以從熟悉的 Microsoft 產品(例如 賓, 科塔娜, Microsoft Edge, 辦公室, SharePoint, Skype以及 Yammer.
Translator 可在任何硬體平台上的網頁或用戶端應用程式中使用,並搭配任何作業系統,以執行語言翻譯及其他語言相關作業,例如語言偵測、文字轉語音或字典。
開發人員利用業界標準的 REST 技術,將原始文字 (或語音翻譯的音訊) 傳送至服務,並附上指示目標語言的參數,然後服務傳回翻譯好的文字,供用戶端或網頁應用程式使用。
Translator 服務是在 Microsoft 資料中心託管的 Azure 服務,可受惠於其他 Microsoft 雲端服務也有的安全性、可擴充性、可靠性和不間斷可用性。
語音翻譯
Translator 語音翻譯技術於 2014 年底從 Skype Translator 開始推出,並於 2016 年初起以開放式 API 供客戶使用。它已整合至 Microsoft Translator 即時功能、Skype、Skype 會議廣播,以及 Android 和 iOS 版 Microsoft Translator 應用程式。
語音翻譯現在可透過 Microsoft Speech 提供,這是一套端對端的完全客製化服務,用於語音識別、語音翻譯和語音合成 (文字轉語音)。
文字翻譯如何運作?
用於文字翻譯的技術主要有兩種:傳統的統計機器翻譯 (SMT),以及新一代的神經機器翻譯 (NMT)。
統計機器翻譯
Translator 的統計機器翻譯 (SMT) 實作是建基於微軟十多年來的自然語言研究。現代翻譯系統並非以手工撰寫規則來進行語言間的翻譯,而是從現有的人為翻譯中學習語言間的文字轉換,並利用應用統計學和機器學習的最新進展來處理翻譯問題。
所謂的「平行語料庫」就像現代的羅塞塔石碑(Rosetta Stone),提供許多語言對和領域的上下文中的字、詞和成語翻譯。統計建模技術和高效演算法可協助電腦解決破譯(偵測訓練資料中源語言和目標語言之間的對應關係)和解碼(尋找新輸入句子的最佳翻譯)的問題。Translator 將統計方法的力量與語言學資訊結合,以產生概括性更佳的模型,並帶來更易理解的翻譯。
由於這種方法不依賴字典或語法規則,因此它能提供最佳的詞組翻譯,在這種情況下,它可以使用給定單字周圍的上下文,而不是嘗試執行單字翻譯。對於單字翻譯,我們開發了雙語字典,並可透過以下方式存取 www.bing.com/translator.
神經機器翻譯
翻譯的持續改進非常重要。然而,自 2010 年代中期以來,SMT 技術的效能改善已經停滯不前。透過利用 Microsoft 的 AI 超級電腦(特別是 Microsoft Cognitive Toolkit)的規模和功能,Translator 現在提供神經網路 (LSTM)為基礎的翻譯,使翻譯品質改善進入新的十年。
這些神經網路模型可透過 Azure 上的 Speech 服務以及使用「generalnn」類別 ID 的文字 API 來使用於所有語音語言。
與傳統 SMT 相比,神經網路翻譯在執行方式上有根本性的不同。
以下動畫描述了神經網路翻譯在翻譯一個句子時所經過的各種步驟。由於採用這種方法,翻譯時會考慮到整個句子的上下文,而不是 SMT 技術所使用的只有幾個字的滑動視窗,因此會產生看起來更流暢、更人性化的翻譯。
在神經網路訓練的基礎上,每個單字都會被編碼為 500 維向量 (a),代表其在特定語言對 (例如英文和中文) 中的獨特特性。根據用於訓練的語言對,神經網路會自行定義這些維度應該是什麼。它們可以編碼簡單的概念,例如性別 (女性、男性、中性)、禮貌等級 (俚語、隨意、書面、正式等)、單詞類型 (動詞、名詞等),也可以編碼從訓練資料中得出的任何其他非明顯特性。
神經網路翻譯的步驟如下:
- 每個單字,或更確切地說代表單字的 500 維向量,都會經過第一層「神經元」,將其編碼為 1000 維向量 (b),在句子中其他單字的上下文中代表該單字。
- 一旦所有的單字都被編碼到這些 1000 維向量中,這個過程就會重複數次,每層都可以在完整句子的上下文中對單字的 1000 維表示進行更好的微調(與只能考慮 3 到 5 個單字視窗的 SMT 技術相反)。
- 注意層 (即軟體演算法) 會使用最終輸出矩陣和先前翻譯字詞的輸出,來定義下一步應該翻譯來源句子中的哪個字詞。它也會使用這些計算來捨棄目標語中不必要的字詞。
- 解碼器 (翻譯) 層會將選定的單字 (或更明確地說,在完整句子的上下文中代表這個單字的 1000 維向量) 翻譯成最適當的目標語言對應詞。最後一層 (c) 的輸出隨後會饋入注意力層,以計算應該翻譯來源句子中的下一個單字。

在動畫中描繪的範例中,情境感知 1000 維模型的"的" 會編碼名詞 (房子) 在法語中是一個陰性詞 (la maison).這將允許適當的翻譯為 "的「成為」啦「,而不是」勒「(單數,男性)或」女同"(複數)一旦到達解碼(翻譯)層。
注意力演算法也會根據先前翻譯的字詞(在本例中為 "的「),下一個要翻譯的字應該是主語(」房子「),而不是形容詞(」藍色").In 可以做到這一點,是因為系統了解到英文和法文在句子中會顛倒這些字詞的順序。它也會計算出如果形容詞是"大「而不是顏色,這樣它就不會反轉它們(」大屋" => "LA GRANDE MAISON").
得益於這種方法,在大多數情況下,最終輸出比基於 SMT 的翻譯更流暢、更接近人類翻譯。
語音翻譯如何運作?
Translator 也能翻譯語音。此技術在 Translator live 功能 (http://translate.it)、翻譯器應用程式、Skype 翻譯器,而且最初僅透過 Skype 翻譯器功能以及 iOS 和 Android 上的 Microsoft 翻譯器應用程式提供,現在開發人員可透過 Azure 入口網站提供的最新版開放式 REST 型 API 使用此功能。
儘管乍看之下,從現有的技術磚塊建立語音翻譯技術似乎是一個簡單直接的過程,但它所需要的工作遠比簡單地將現有的「傳統」人機語音辨識引擎插入現有的文字翻譯引擎要多得多。
為了將「源」語言從一種語言正確地翻譯成不同的「目標」語言,系統會經過四個步驟。
- 語音辨識,將語音轉換為文字
- TrueText:一項 Microsoft 技術,可將文字規範化,使其更適合翻譯
- 透過上述文字翻譯引擎進行翻譯,但採用專為真實生活口語會話開發的翻譯模型
- 文字轉語音(Text-to-speech),必要時可製作翻譯音訊。

自動語音辨識 (ASR)
自動語音辨識 (ASR) 是使用一個神經網路 (NN) 系統來執行,該系統是在分析數千小時的輸入音訊語音後訓練而成。此模型是根據人與人之間的互動而非人對機的指令訓練而成,可針對一般對話進行最佳化的語音辨識。為了達到這個目標,需要比傳統人機互動 ASR 更多的資料以及更大的 DNN。
進一步了解 Microsoft 的語音轉文字服務.
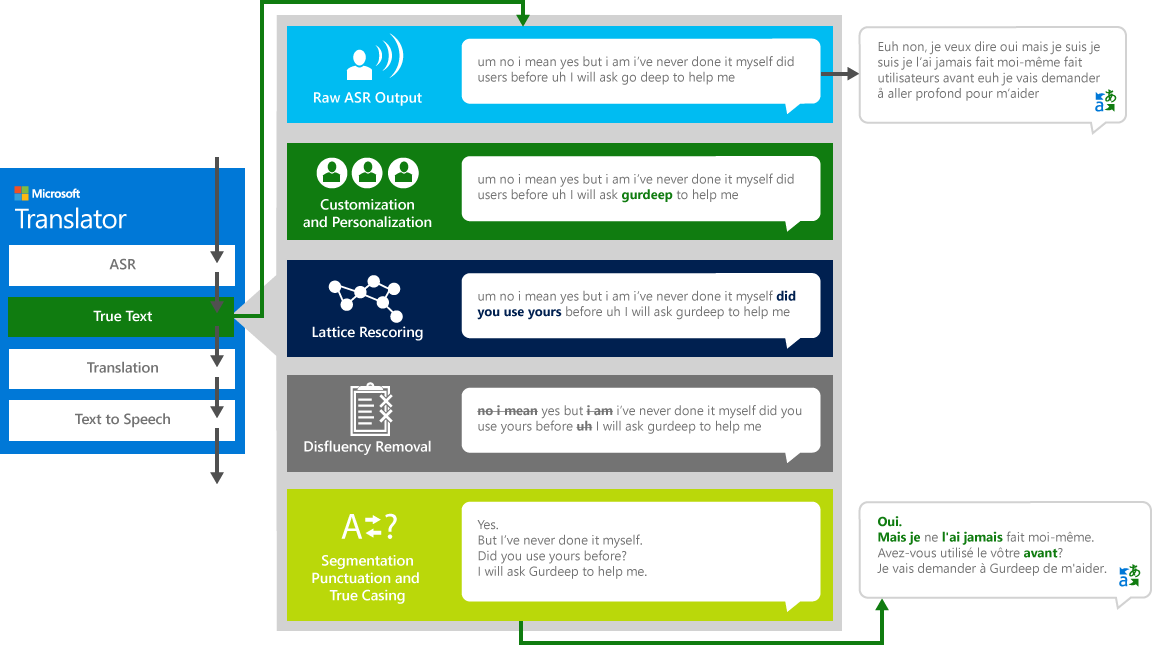
TrueText
人與人之間的對話,並不像我們經常認為的那樣完美、清晰或整潔。有了 TrueText 技術,字面上的文字會被轉換為更貼近使用者的意圖,去除語音不流暢 (填充字),例如 "um"、"ah"、"and"、"like"、口吃和重複。此外,我們也加入了分句、正確的標點符號和大小寫,使文字更具可讀性和可翻譯性。為了達到這些效果,我們運用了從 Translator 開發出來的數十載語言技術來創造 TrueText。下圖透過一個真實的範例,描述 TrueText 為了將文字規範化而進行的各種轉換。
翻譯
然後將文字翻譯成任何 語言和方言 由翻譯支援。
使用語音翻譯 API(作為開發者)或在語音翻譯應用程式或服務中進行翻譯時,所有語音輸入支援的語言都可使用最新的神經網路翻譯(請參閱 這裡 的完整清單)。這些模型也是透過擴充目前大多數以書面文字訓練的翻譯模型,再加上更多的口語文字語料來建立的,目的是為口語對話類型的翻譯建立更好的模型。這些模型也可透過 「演講 」標準類別 的傳統文字翻譯 API。
對於任何神經翻譯不支援的語言,則執行傳統的 SMT 翻譯。
文字轉語音
如果目標語言是 18 種支援的文字轉語音之一 語言如果使用個案需要音訊輸出,則會使用語音合成將文字轉換為語音輸出。在語音到文字的翻譯情境中,這個階段會被省略。
進一步了解 Microsoft 的文字轉語音服務.
研究
檢視 Microsoft Translator 團隊的最新研究論文。



