
Make some noise: Teaching the language of audio to an LLM using sound tokens
- Shivam Mehta, KTH Royal Institute of Technology
We investigate the use of low bitrate causal quantized audio representations to fine-tune large language models (LLMs) using LoRA for comprehending and generating audio. Differing from earlier approaches that depend on continuous audio representations for audio comprehension, our attempt involves learning a discretized language of audio through a causal variational quantization leading to an ultra-low bitrate of 0.293 kbps. These proposed audio tokens are then utilized to fine-tune the Llama 7b model for multimodal tasks involving audio understanding and generation. By treating audio as a language with a similar left-to-right inductive bias, we can leverage these tokens to train a multimodal model and conduct qualitative multimodal analysis.

Regardez suivant
-
-
-
-
-
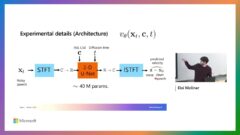
MSR Talk: Unsupervised Speech Reverberation Control with Diffusion Implicit Bridges
- Eloi Moliner,
- Hannes Gamper
-
-
-
-
-








