

GUI-Actor
Coordinate-Free Visual Grounding for GUI Agents
One of the principal challenges in building VLM-powered GUI agents is visual grounding, i.e., localizing the appropriate screen region for action execution based on both the visual content and the textual plans. We revisit recent coordinate generation-based approaches for visual grounding in GUI agents, identify their limitations—such as weak spatial-semantic alignment, ambiguous supervision targets, and mismatched feature granularity—and propose GUI-Actor, a novel coordinate-free method that effectively addresses these issues.
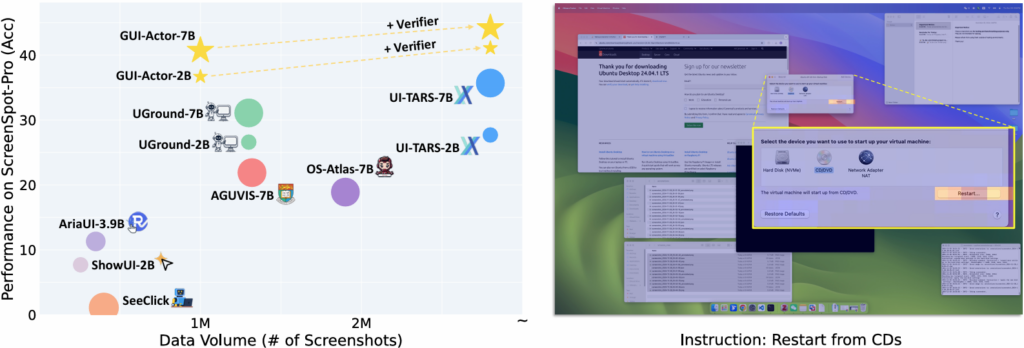
Figure 1. Left: Model performance vs. training data scale on the ScreenSpot-Pro benchmark. Higher and more left is better; larger points indicate models with more parameters. We only show GUI-Actor models built upon Qwen2-VL here for fair comparison. With Qwen2.5-VL as the backbone, GUI-Actor-3B/7B reaches scores up to 42.2/44.6 (without Verifier). Right: Illustration of action attention. GUI-Actor grounds target elements by attending to the most relevant visual regions.
Key Takeaways
🤔 We identify several limitations in coordinate-generation based methods (i.e., output screen positions as text tokens x=…, y=…) for GUI grounding, including (1) weak spatial-semantic alignment, (2) ambiguous supervision signals, and (3) granularity mismatch between vision and action space.
💡 Rethink how humans interact with digital interfaces: humans do NOT calculate precise screen coordinates before acting—they perceive the target element and interact with it directly.
🚀 We propose GUI-Actor, a VLM enhanced by an action head, to mitigate the above limitations. The attention-based action head not only enables GUI-Actor to peform coordinate-free GUI grounding that more closely aligns with human behavior, but also can generate multiple candidate regions in a single forward pass, offering flexibility for downstream modules such as search strategies.
➕ We design a grounding verifier to evaluate and select the most plausible action region among the candidates proposed from the action attention map. We show that this verifier can be easily integrated with other grounding methods for a further performance boost.
🎯 GUI-Actor achieves state-of-the-art performance on multiple GUI action grounding benchmarks with the same Qwen2-VL backbone, demonstrating its effectiveness and generalization to unseen screen resolutions and layouts. Notably, GUI-Actor-7B even surpasses UI-TARS-72B (38.1)on ScreenSpot-Pro, achieving scores of 40.7 with Qwen2-VL and 44.6 with Qwen2.5-VL as backbones.
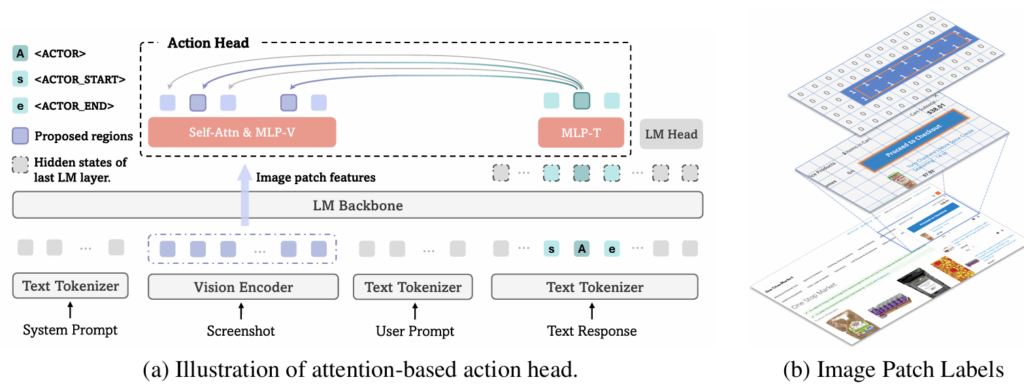
Figure 2. Overview of GUI-Actor. (a) Illustration of how the action head works with a VLM for coordinate-free GUI grounding. (b) Illustration of the spatial-aware multi-patch supervision for model training. We label all image patches that are partially or fully covered by the ground-truth bounding box as positive (1) and all others as negatives (0).
Main Results
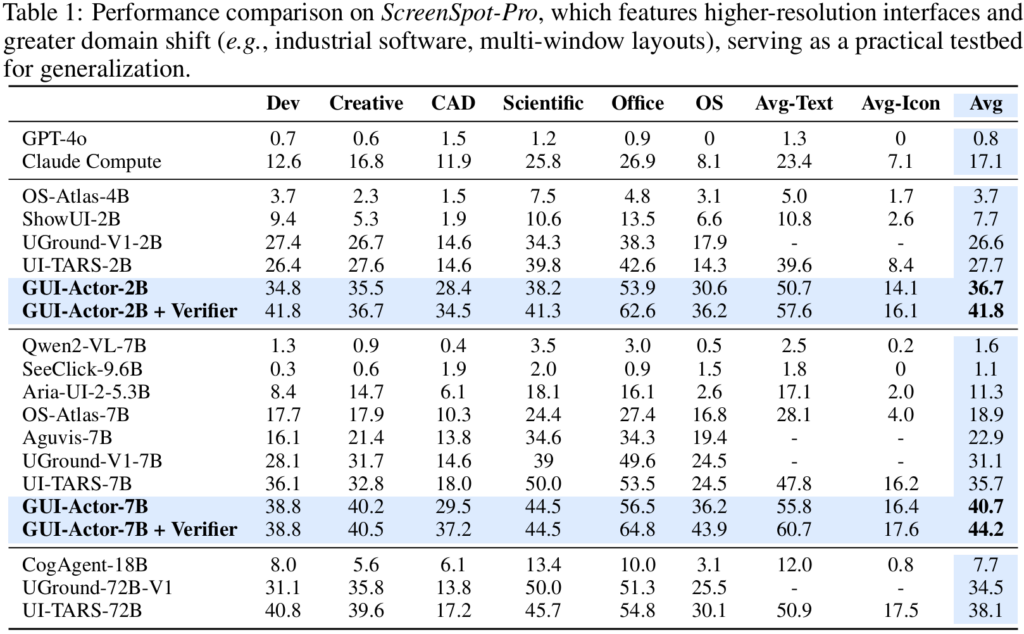
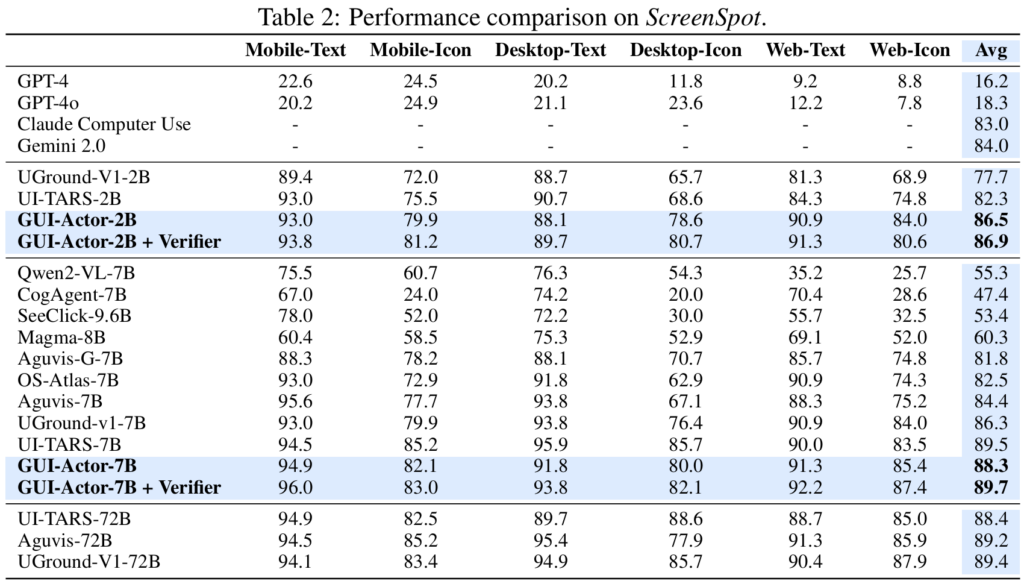
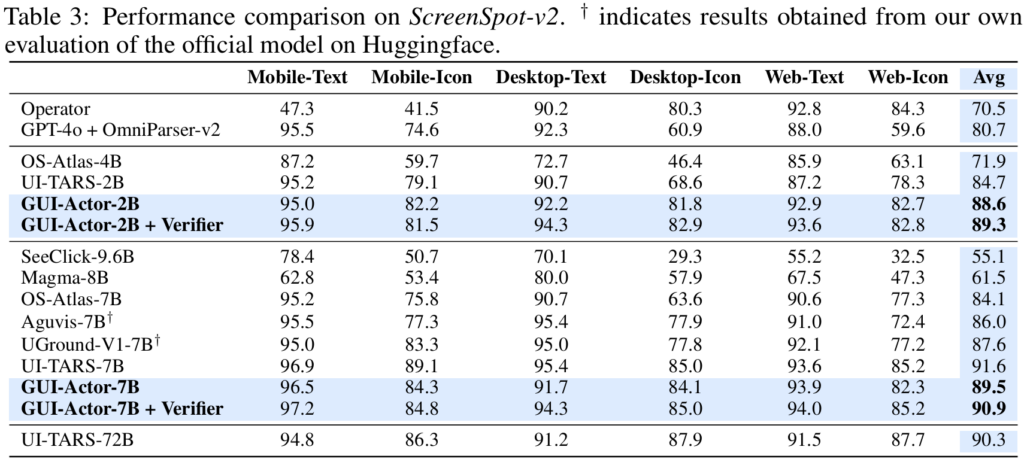
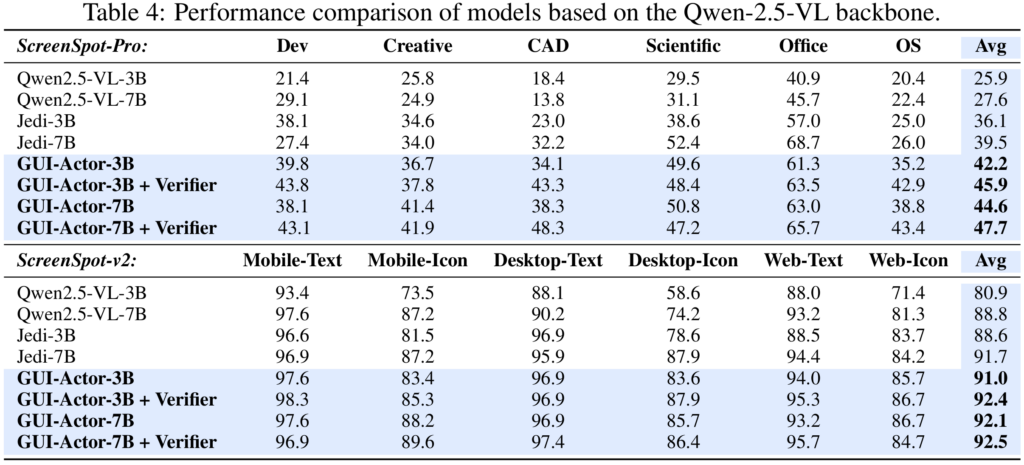
Table 1, 2, 3, and 4 present performance comparisons on ScreenSpot-Pro, ScreenSpot, and ScreenSpot-v2 benchmarks. Our GUI-Actor-2B and GUI-Actor-7B, consistently outperform existing state-of-the-art methods across all benchmarks, with the 2B model even surpassing many competing 7B models. While there is one exception UI-TARS-7B achieving stronger performance, it benefits from training on a significantly larger dataset that includes both public and proprietary data (see Figure 1). Additionally, it undergoes a more extensive training pipeline, including continual pre-training, an annealing phase, and a final stage of direct preference optimization (DPO). Although our models are trained solely with supervised fine-tuning, they achieve competitive or even superior results on ScreenSpot-Pro, demonstrating its strong capability and potential.
Robust Out-of-Distribution Generalization
As shown in Table 1 and Table 4, GUI-Actor models demonstrate strong performance on ScreenSpot-Pro—an out-of-distribution benchmark characterized by higher resolutions and substantial domain shifts from the training data—surpassing the previous state-of-the-art UI-TARS model by +9.0 and +5.0 points with 2B and 7B parameters, respectively. We attribute this gain to explicit spatial-semantic alignment: unlike coordinate-based approaches such as UI-TARS, GUI-Actor leverages an attention-based action head that grounds semantic cues directly in discrete visual regions. This design embeds a stronger spatial inductive bias and naturally aligns with the patch-based representations of modern vision backbones. As a result, GUI-Actor is better equipped to reason over localized visual content, enabling robust generalization across diverse screen resolutions and UI layouts.
Enabling backbone VLM grounding on GUIs without sacrificing general-purpose strengths.
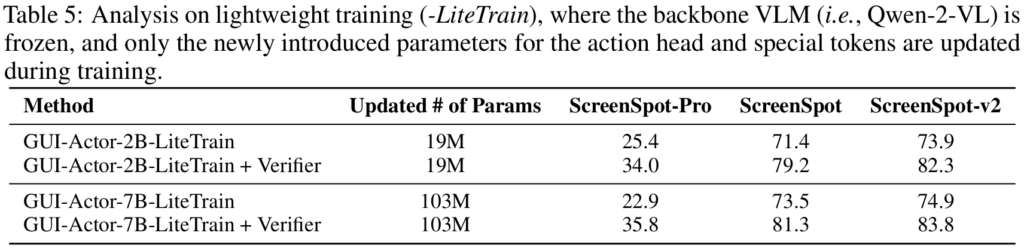
We introduce a variant, GUI-Actor-LiteTrain, where we freeze all backbone VLM parameters and train only the newly introduced components for the action head and special tokens. This setup explores how GUI-Actor can impart GUI grounding capabilities without diminishing the VLM’s general-purpose strengths. As shown in Table 5, GUI-Actor-LiteTrain yields substantial performance improvements over the unmodified backbone VLM. With the help of a grounding verifier, it even rivals fully fine-tuned coordinate generation models. These results suggest that the backbone VLM already exhibits strong perceptual understanding of UI screenshots. As such, training the model to generate coordinates in text format may primarily focus on coordinate mapping, offering limited contribution to the semantic understanding of UI elements. More importantly, GUI-Actor-LiteTrain retains the backbone’s original language and vision-language capabilities, demonstrating that lightweight integration can enable grounding without compromising generality.
Multi-Region Prediction Without Extra Inference Cost
Due to its attention-based grounding mechanism, GUI-Actor can generate multiple candidate action regions in a single forward pass, incurring no extra inference cost. To evaluate the effectiveness of these high-probability regions, we use the Hit@k metric, where k represents the number of top-ranked predictions considered. Figure 3a shows that GUI-Actor exhibits a substantial improvement from Hit@1 to Hit@3, whereas the gap for baselines is relatively marginal. In our analysis, we observed that for coordinate-generation-based baselines, even when multiple predictions are sampled, the outputs are mostly identical, e.g., shifting slightly from (0.898, 0.667) to (0.899, 0.666). In contrast, our model simultaneously produces multiple candidate regions from the attention distribution in a single forward pass. These candidates are mutually exclusive, naturally promoting diversity and increasing the chance of capturing all valid action regions. Figure 3b provides a qualitative example where our approach successfully identifies all ground-truth regions required for action execution.
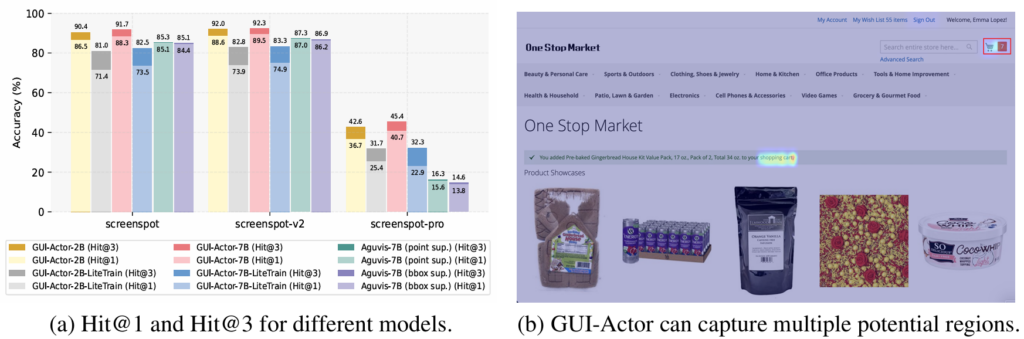
Figure 3. (a) Hit@1 and Hit@3 for different methods. For Aguvis baselines, we run inference 3 times with temperature = 1.0, top_p = 0.95. (b) Illustration of multi-region prediction. In this example, the instruction is «check shopping cart» and the central «shopping cart» text is clickable, while the ground truth is only the top-right icon.
BibTex
@article{wu2025gui,
title={GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents},
author={Wu, Qianhui and Cheng, Kanzhi and Yang, Rui and Zhang, Chaoyun and Yang, Jianwei and Jiang, Huiqiang and Mu, Jian and Peng, Baolin and Qiao, Bo and Tan, Reuben and others},
journal={arXiv preprint arXiv:2506.03143},
year={2025}
}