

Agent Lightning
Optimize ANY agent with ANY framework
We present Agent Lightning (opens in new tab), a flexible and extensible framework that enables seamless agent optimization for any existing agent framework. Here agent optimization includes various data-driven techniques to customize the agent for better performance, including but not limited to model fine-tuning, prompt tuning, model selection, etc. And the agent frameworks refer to popular and easy-to-use agent developing frameworks such as OpenAI Agents SDK, Microsoft AutoGen, and LangChain. By bridging the gap between agent workflow development and agent optimization, Agent Lightning empowers developers to go beyond static, pre-trained models and unlock the full potential of adaptive, learning-based agents.
AI agents have emerged as a powerful paradigm for solving complex real-world problems, such as search, code generation, and interactive task completion, thanks to their interactivity, composability, and modularity. To facilitate rapid agent development, various agent orchestration frameworks like OpenAI Agent SDK and LangChain have been introduced, offering intuitive APIs for defining agent capabilities and interactions. However, these frameworks lack native support for automatic agent optimizating, such as model training, limiting their applicability in private-data scenarios and real-world deployment.
Conversely, existing model training frameworks — whether based on supervised learning or reinforcement learning (RL) — often fail to address challenges inherent in agent applications, which come from multi-turn interactions, multi-agent coordination, dynamic contexts, complex logic, and so on. While RL is particularly well-suited for optimizing long-term interactions and user experiences, current RL training tools offer little to no compatibility with agent frameworks.
Agent Lightning targets on filling this critical gap. It can optimize ANY agent built with ANY framework. Currently, the focus is training models of agents via RL. Our system collects interaction data using popular agent frameworks and leverages powerful RL infrastructure like verl for model optimization. By decoupling agent framework from RL training system, Agent Lightning can be seamlessly enables model training for any existing agent, without requiring any modifications to the agent code. It allows model training to be directly aligned with the agent’s real deployment behavior and task logic, resulting in improved performance and adaptability.
Highlights
Seamless Integration with Any Agent Framework
Agent Lightning supports optimizing for agents built with any framework (e.g., OpenAI Agent SDK, LangChain and AutoGen), with no modifications needed to either the agent development code.
Decoupling Agent Workflow Development and Optimization Framework
By introducing the Lightning server and client that bridges verl training infrastructure and agents, our framework cleanly decouples agent logic from training logic, enabling easy, plug-and-play adoption across diverse applications.
Optimized for Real-World Agent Scenarios
Agent Lightning is built to handle the complexities of real-world agent applications, including multi-turn interactions, context/memory management, and multi-agent coordination, enabling continuous learning and improved performance in dynamic, real settings.
Built-in Error Monitoring
Complex agent systems often fail to complete tasks due to execution errors or get stuck in unrecoverable states, posing significant challenges for the optimization process. Agent Lightning supports agent-side error monitoring. The Lightning Server can track agent execution status, detect failure modes, and report detailed error types. This gives optimization algorithms sufficient signal to handle edge cases gracefully and maintain stable optimization process even in the presence of imperfect agents, which might be common during training.
Framework overview
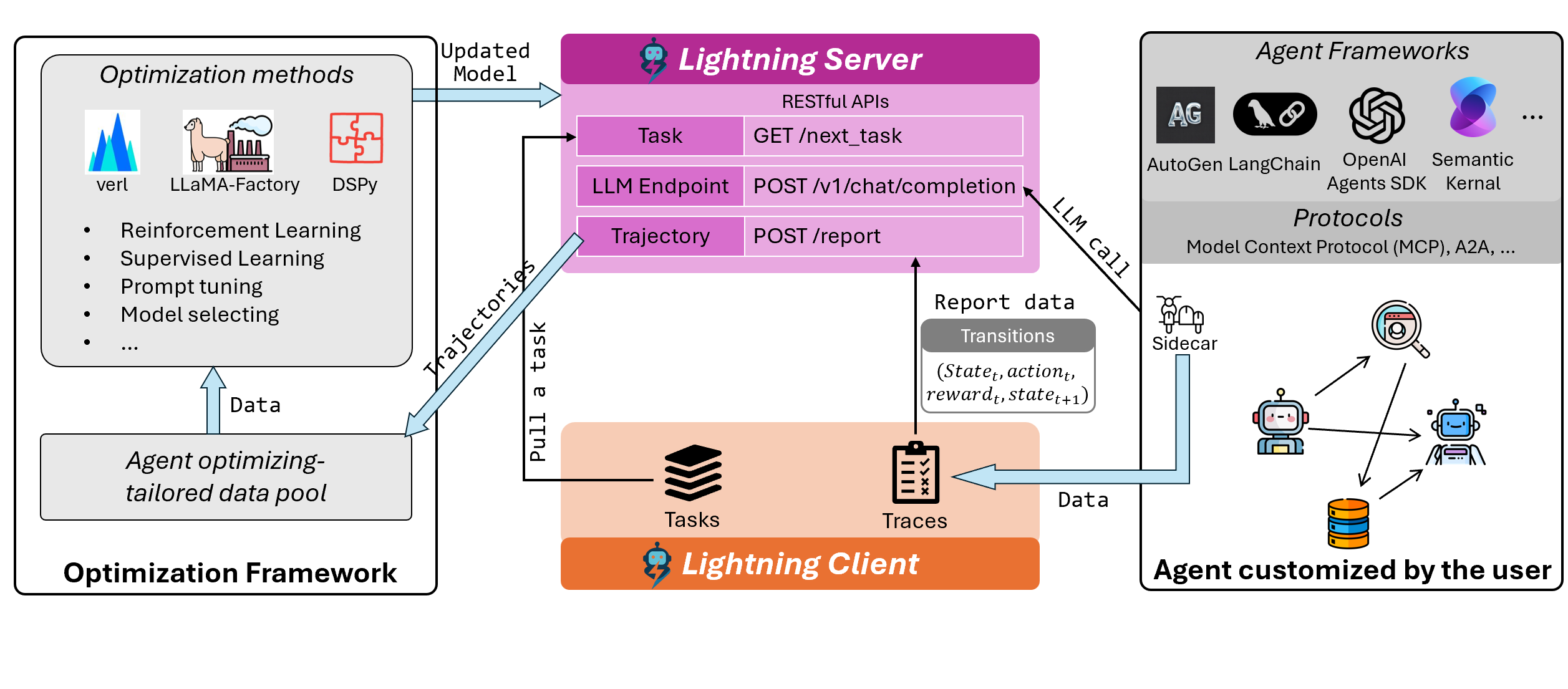
Agent Lightning is composed of two core modules: the Lightning Server and Lightning Client. Together, they bridge the gap between agent frameworks and LLM training frameworks by serving as a thin, flexible intermediate layer. In particular, we expose an OpenAI-compatible LLM API inside the training infrastructure (currently based on verl (opens in new tab)), allowing seamless integration with any existing agent framework without modifying the agent code. This makes it possible to plug in and train real-world agents with complex interaction logic across diverse agent systems (currently we support OpenAI Agent SDK (opens in new tab), LangChain (opens in new tab), and AutoGen (opens in new tab)).
How It Works (Example: RL Training with verl)
- Task Pulling & Agent Execution
The Lightning Server pulls a task from the task pool and send it to the agent side. The agent attempts to complete the task using its native workflow. This may involve multi-agent coordination, tool usage, multi-turn interactions, and many complex logics. - Non-Intrusive Trace Collection (Sidecar Design)
We adopt a sidecar-based design to non-intrusively monitor agent runs, and collect data (including execution traces, errors, and reward signals which can be customized by the user to reflect task success or failure) via the server’s reporting API. Traces are converted into a standard transition tuple (statet, actiont, rewardt, statet+1), indicating the current state, the taken action at current state, received immediate reward and the next state. - Trajectory Organization & Training Loop
These traces are aggregated into training-ready data structures, tailored for LLM optimization. The training framework (e.g., verl) then uses reinforcement learning algorithms such as GRPO to update the model. The updated model is used in the next rollout cycle, creating a tight feedback loop between agent behavior and learning.
Above designs services model training as a standalone module, cleanly decoupled from agent workflow development logic. As a result, Agent Lightning enables seamless and scalable integration with any agent framework, while fully supporting real-world complexities like memory, context, and multi-agent workflows.
Upcoming features
We are actively expanding Agent Lightning to support more features, for achieving more advanced and capable agents in real-world scenarios.
For the RL side, the first part is about richer feedback and reward mechanisms, including user feedback, tool success signals, long-horizon credit assignment, and so on. The second aspect is about integration of advanced RL optimization (e.g., off-policy algorithms, hierarchical RL), online supervised fine-tuning, curriculum learning, and more.
Our current focus is on RL-based optimization methods, as they naturally leverage task success signals as supervision to guide model training. However, the design philosophy of Agent Lightning is not limited to RL. Instead, we aim to build a unified framework for diverse agent optimization methods, including but not limited to training-free approaches such as prompt tuning and model selection. Different optimization techniques may be more suitable for different models or deployment settings, and Agent Lightning is built to support this flexibility.
Besides, more optimization backends (e.g., LLaMA-Factory, DSPy) and broader agent framework compatibility (e.g., Semantic Kernel, CrewAI, MetaGPT) are also considered.