

微软亚洲研究院
新闻与深度文章

编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉。 6月10日至17日,全球计算机视觉领域的顶尖学术盛会 CVPR 在美国田纳西州纳什维尔举办。我们通过两期“科研上新”为大家带来多篇微软亚洲研究院入选 CVPR 2025 的精选论文解读。第一期分享的内容主要围绕生成模型与扩散技术等方向的研究…

编者按:在 MBTI 测试风靡的当下,人们热衷于探寻自己究竟是充满活力的“快乐小狗”,还是敏感细腻的“流泪猫猫”。当大模型逐渐成为人们生活中不可或缺的助手时,你是否会好奇:这些大模型有着怎样的特性,或者说,它们秉持何种不同的价值观? 微软亚洲研究院最新发布的 Value Compass Benchmarks(价值观罗盘评估中心),可以帮助用户以更科学、系统和可靠的方式,对大模型的价值观展开评估。同…

编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉。 6月10日至17日,全球计算机视觉领域的顶尖学术盛会 CVPR 将在美国田纳西州纳什维尔举办。我们将通过两期“科研上新”为大家带来多篇微软亚洲研究院入选 CVPR 2025 的精选论文解读。第一期的分享内容是主要围绕生成模型与扩散技术等方向…
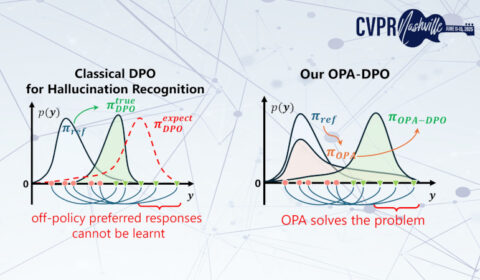
编者按:在视觉多模态大语言模型的快速发展中,幻觉问题一直是研究者们关注的焦点。模型生成与输入图像不一致甚至虚假的内容,不仅影响用户体验,也阻碍了多模态技术在实际场景中的落地。对此,微软亚洲研究院和香港中文大学的联合研究团队从直接偏好优化(DPO)入手,提出了 On-Policy Alignment (OPA)-DPO 算法,可通过确保训练数据与初始策略(reference policy)的一致性,…

编者按:随着应用场景的扩展,端侧设备(如手机、电脑、可穿戴设备、机器人等)对大模型高效运行的需求日益增长,但端侧设备对模型运行的计算资源、访存带宽、能耗都有着极其苛刻的要求。存内计算技术有望从根本上解决以上资源问题,它能够将存储单元和计算单元融合,显著减少数据在存储和计算单元间频繁搬运而产生的资源损耗。然而,传统存内计算涉及对硬件架构的改动,不仅技术难度大,且迭代周期长,无法在实际场景中大规模量产…

编者按:在产业智能化加速发展的当下,时间序列数据已然成为智能决策系统的关键基石。然而,传统的时间序列生成模型往往难以应对跨领域、跨风格的数据需求,且生成的数据在实际应用中缺乏可控性和实用性。 为解决这些痛点,微软亚洲研究院推出开源框架 TimeCraft,融合多项研究成果,通过跨域泛化、自然语言控制与任务感知等创新技术,助力时间序列生成任务从结构理解到任务对齐的全流程能力建设。TimeCraft…

以人工智能大模型的崛起为标志,计算机科学踏入了一望无垠的未知之境。我们对技术变革带来的无限可能满怀期待,却也在颠覆性的重塑中遭遇诸多困惑与挑战: 新的研究范式已然到来,如何发现并投身于具有持久影响力的研究方向?面对无先例可循的技术“无人区”,突破性创新需要怎样的思维破壁?AI时代,需要什么样的人才?什么样的成长环境能够激发人才的潜能?企业如何构建持续创新的内生动力?前沿成果又该以何种方式、何种形态…
编者按:尽管近年来人工智能的能力迅速增强,但在复杂的推理任务中仍存在不足。微软亚洲研究院的研究员们从多个角度对此展开研究,不断探索提升大模型推理能力的新途径。从利用蒙特卡洛树搜索模拟人类“深度思考”过程的 rStar-Math,到基于规则的强化学习方法 Logic-RL;从融合大语言模型数学直觉与符号方法的 LIPS,到提升自动形式化准确性的新框架;再到自动生成高质量、有监督数学数据的神经符号框架…

作者:工程与基础架构组 编者按:随着代码大模型能力的不断增强,高质量指令数据的构造成为释放其潜力的关键。然而,现有方法普遍依赖单一的代码片段作为构造种子,限制了数据的复杂度与多样性。近日,微软亚洲研究院联合厦门大学、清华大学提出全新特征树驱动的数据合成框架,通过建模代码语义层级关系,实现了对合成代码复杂度的精细控制,并支持从函数级到多文件级的多样任务生成。基于该框架训练得到的 EpiCoder 模…