

编者按:近年来,大模型在多模态交互中的应用不断深入,使得人机交互中的“理解能力”面临新的挑战。特别是在 Compute Use Agent 的发展背景下,如何准确理解用户的自然语言指令并将其映射到复杂 GUI 界面中的相应元素(即 “GUI Grounding” 任务)成为关键。然而,现有的公开数据集难以全面覆盖真实使用场景中的各种难点。对此,微软亚洲研究院提出了 UI-E2I-Synth,不仅构建了大规模高质量合成数据集,还推出了更具挑战性与现实性的测试基准 UI-I2E-Bench,系统性解决了当前任务中的三大关键问题。相关论文已被 ACL 2025 收录。
随着多模态智能体在复杂人机交互任务中的应用不断被拓展,大模型理解和操作图形用户界面(GUI)的能力正变得日益关键。GUI Grounding,即根据用户的自然语言指令,准确定位屏幕截图中对应的界面元素,已成为当前 Compute Use Agent 开发中的核心挑战之一。
然而,现有的公开训练数据集规模有限,且高质量指令的人工标注成本高昂,制约了该任务的进一步发展。当前研究面临着三个尚未被充分探索的关键问题:
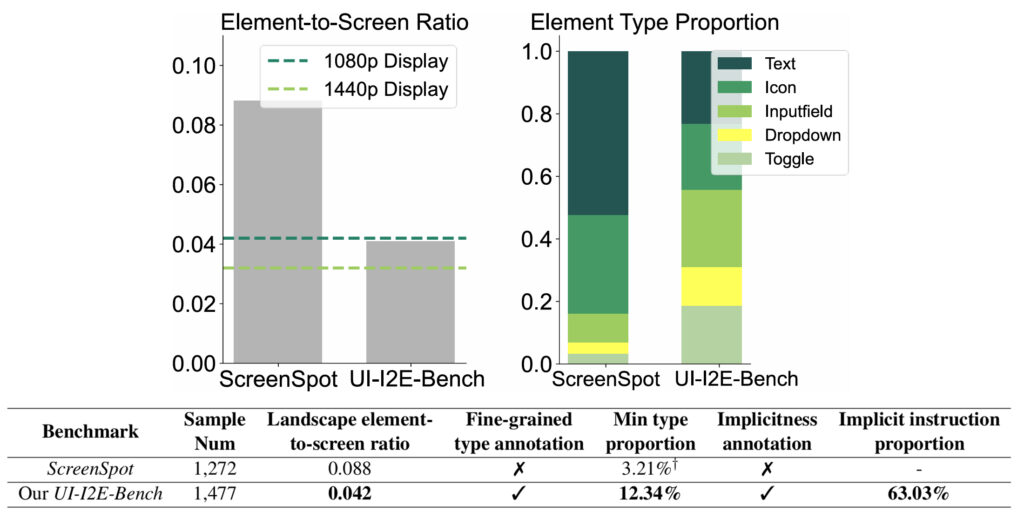
1. 元素与屏幕的比例失真:现有基准测试(如ScreenSpot)的界面元素相对屏幕明显偏大,远离真实用户场景中的高分辨率、小元素界面。这可能导致模型的性能被高估。
2. 元素类型分布失衡:不同类型的 GUI 元素(如文本按钮、复选框等)具有不同的视觉风格和交互方式。但现有基准中文本和图标类型占比过高,缺乏对其他类型的覆盖。
3. 隐式指令理解能力弱:现实用户在发出指令时往往依赖于对元素功能或位置的直观理解,而非直接引用屏幕上的可见文本,这类“隐式指令”对视觉语言模型(VLMs)的理解和推理能力提出了更高的要求。
针对这些问题,研究员们提出了一个端到端的大规模数据合成方法 UI-E2I-Synth,并使用半自动方式构建了一个全新的测试基准 UI-I2E-Bench。相关论文已被 ACL 2025 接收。
UI-E2I-Synth: Advancing GUI Grounding with Large-Scale Instruction Synthesis
论文链接:https://arxiv.org/abs/2504.11257 (opens in new tab)
GitHub 链接:https://github.com/microsoft/FIVE-UI-Evol/tree/main (opens in new tab)
UI-I2E-Bench Leaderboard 链接:https://microsoft.github.io/FIVE-UI-Evol (opens in new tab)
构建从数据到模型的完整链条:合成方法、评测基准与VLM性能突破
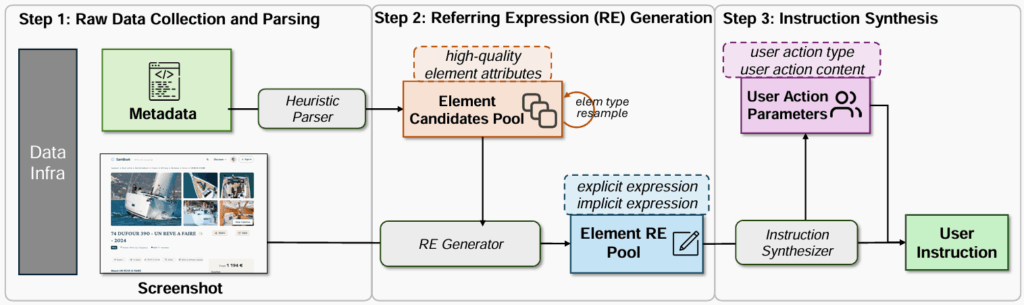
UI-E2I-Synth 的核心在于,利用大语言模型(如GPT-4o)而非人工标注来合成各种复杂度的真实指令。该管道遵循“分而治之”原则,整体流程分为三个步骤:
首先是原始数据的收集与解析。从网页、Windows 和 Android 等多个平台收集截图-元数据对,使用启发式解析器提取元素类型、内容和边界框等可靠属性,以缓解幻觉问题,确保结构可靠且可用于后续建模。其次是指代表达式(referring expressions, RE)生成。结合 Set-of-Marks 截图和元素属性,通过 GPT-4o 生成显式和隐式两种类型的指代表达式,以增加指令的多样性。最后是指令合成。再次利用 GPT-4o 模拟用户行为,生成特定的动作参数(如点击、输入内容),并与指代表达式结合,合成最终的真实用户指令。
在合成数据的基础上,研究员们通过人工精校的方式引入了一个全新的测试基准 UI-I2E-Bench。该基准纳入了更丰富的标注维度,包括元素类型、元素与屏幕的比例、指令隐含程度等,为未来的 GUI Grounding 模型开发提供了进一步的见解。
利用 UI-E2I-Synth 生成的990万条指令数据,研究员们训练了 UI-I2E-VLM-4B 和 UI-I2E-VLM-7B。评估结果显示,UI-I2E-VLM-7B 在 UI-I2E-Bench、ScreenSpot 和 ScreenSpot-Pro 等基准测试中,使用更少的训练数据(仅为 OS-Atlas 的72%)就取得了优异的表现。UI-I2E-VLM 在处理隐式指令和小元素(低元素-屏幕比例)方面表现出显著优势,并提升了对图标和输入框等长尾元素类型的识别能力。研究还发现,现有基准如 ScreenSpot 可能因其较低的难度高估了模型性能。
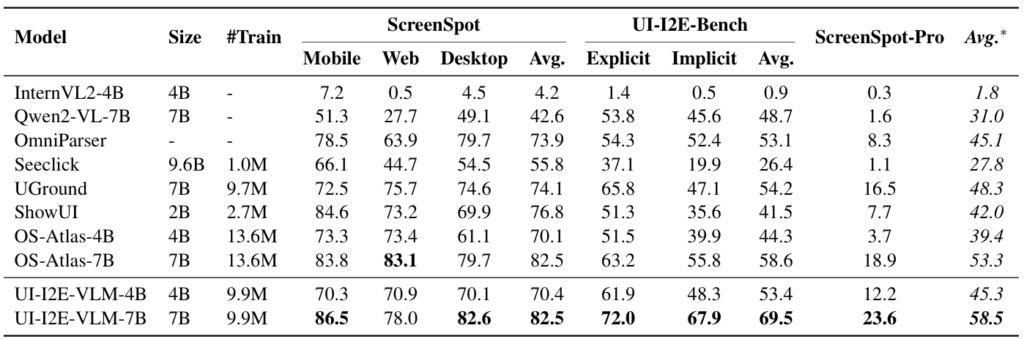
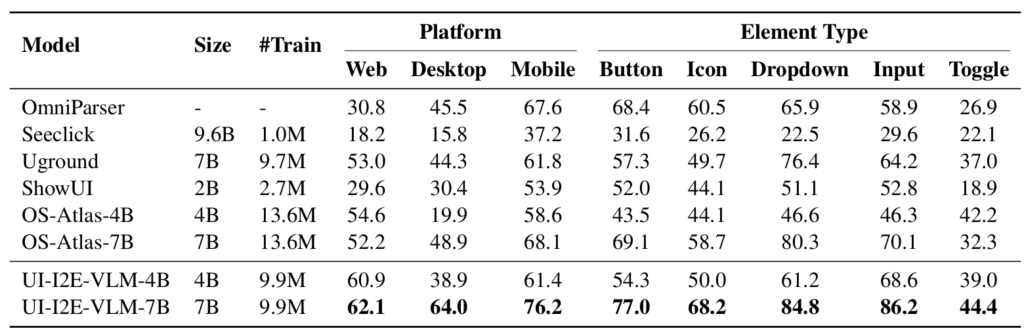
借助 UI-I2E-Bench 的细致标注,研究员们进一步对模型性能展开了诊断分析,发现针对指令类型,模型在处理隐式指令时提升显著,而以往低估了指令的复杂性。例如,领先模型 OS-Atlas-7B 在此维度上落后12.1个百分点。OmniParser 依托 GPT-4o,在隐式指令任务上表现突出,但在显式指令上表现一般,其主要瓶颈在于细小和长尾元素的定位。关于元素与屏幕比例,分析结果显示元素尺寸越小,其准确率下降越明显。这说明小尺寸元素和高分辨率图像对基准测试至关重要。UI-I2E-VLM 凭借更丰富的训练数据和更多输入图像 token,在小尺寸元素定位上表现更佳。在元素类型方面,现有模型在“图标”和“输入框”这类长尾类别上的表现存在明显短板。对此,UI-E2I-Synth 通过均衡元素类型分布,提升了模型对这些类别的处理能力。
重塑评估标准,赋能智能交互未来
UI-E2I-Synth 和 UI-I2E-Bench 的提出,不仅解决了 GUI Grounding 训练与评估中的关键问题,也为未来智能助手在真实 GUI 场景中的部署奠定了基础。
通过深入理解指令多样性与 UI 复杂性的关系,研究员们为多模态模型能力的提升打开了新的空间,也为行业提供了更具挑战性、更有指导意义的基准标准。



