One of the driving forces behind AI’s rapid progress is access to large-scale, high-quality data, essential to enable training models to continuously improve and perform reliably. But that well is running dry. As the supply of usable internet data shrinks, it’s becoming harder and more expensive to gather the kind of training data AI needs. Researchers call this challenge the “data wall”—a barrier that slows development and increases costs.
To break through this wall, many are turning to synthetic data. Though it’s artificially generated, synthetic data can closely mimic real-world patterns. What hasn’t been clear is whether the same rules that govern model performance with natural data, known as scaling laws, also apply to synthetic data.
In natural datasets, LLMs tend to follow a predictable power-law relationship among performance, model size, and the amount of training data. This helps researchers estimate how well a model will perform based on available resources.
To find out whether synthetic data follows these same scaling laws, Microsoft Research Asia created SynthLLM, a system for generating synthetic data at scale based on pretraining corpus. After extensive testing, the team confirmed that these scaling laws do hold, laying the groundwork for synthetic data to play a larger role in training and optimizing large language models (LLMs).
Synthetic data follows a new scaling pattern
Using the SynthLLM framework, researchers have shown that LLMs fine-tuned on synthetic data do follow a modified version, what they call a rectified scaling law. Key findings include:
- Predictable performance scaling: Synthetic data generated by SynthLLM produces consistent performance gains across different model sizes. This predictability helps researchers match training data volumes more effectively to model size.
- Performance levels off at 300 billion tokens: Beyond this point, adding more synthetic data brings only minor improvements. Identifying this plateau makes it easier to optimize training strategies.
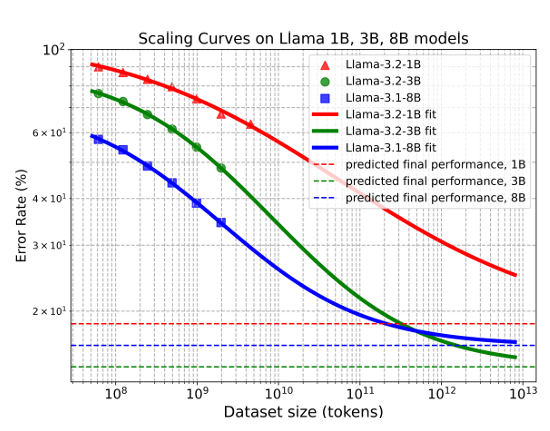
- Larger models need less data: An eight-billion-parameter model reaches near-optimal performance with one trillion tokens, while a smaller three-billion-parameter model needs four trillion, as shown in Figure 1. This inverse trend offers useful guidance for building and scaling models efficiently.
SynthLLM: A scalable approach to diverse synthetic datasets
One common strategy for training language models is to use question-and-answer pairs as data, especially for tasks like reasoning, problem-solving, or knowledge retrieval. Traditionally, synthetic datasets of this kind rely on a small number of manually labeled seed samples, an approach that limits both scale and variety. In contrast, the vast, diverse collections of web documents used in pretraining offer an underused resource for building more scalable synthetic data.
SynthLLM builds on this potential with a three-stage process:
- Selecting high-quality web content related to the domain.
- Generating prompts with open-source LLMs, using three complementary methods that progressively increase the variety of questions.
- Producing answers foreach prompt to create complete data samples.
Unlike earlier methods that depend on back-translation or simple question extraction, SynthLLM uses graph algorithms to identify and recombine high-level concepts from multiple documents. This allows it to create deeper conceptual connections, and to more efficiently take advantage of limited reference documents to scale diverse questions.
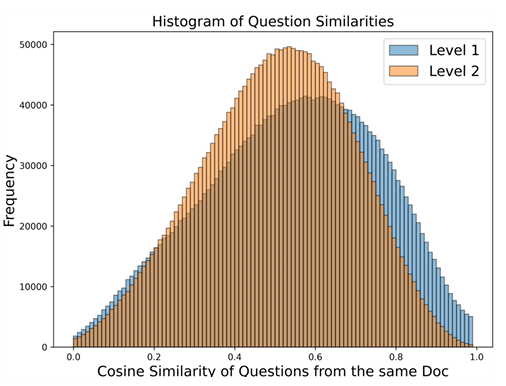
The result? A broader range of synthetic questions. Figure 2 shows that SynthLLM’s multi-step process leads to greater diversity.
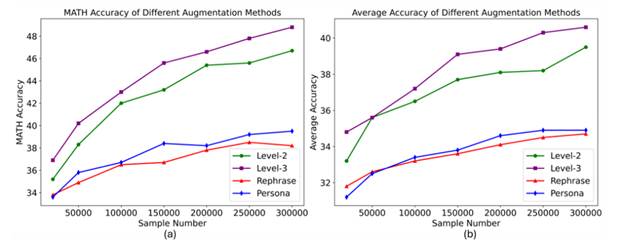
In direct comparisons with existing methods for expanding training data, SynthLLM’s knowledge-guided approach makes better use of limited source material to generate high-quality questions. This leads to stronger model performance across benchmarks, as illustrated in Figure 3.
A renewable resource for training data
As the data wall continues to rise, synthetic data is emerging as an essential resource for AI development. It’s scalable, fast to produce, cost-effective, and doesn’t require manual labeling—making it a practical solution to growing data shortages.
Its value spans a range of fields. In healthcare, it protects patient privacy. In autonomous driving, it powers virtual simulations. In education, it enables the creation of millions of math problems on demand.
SynthLLM simplifies the generation of synthetic data, helping researchers make better use of it to train LLMs. The framework is adaptable to domains like code generation, physics, chemistry, and healthcare—broadening its potential to support research across disciplines.
Researchers are now working to further improve SynthLLM’s efficiency and explore its use in continue pretraining. These efforts aim to raise the quality and broaden impact of synthetic data, helping drive the next wave of AI development.