Imagine a pair of smart glasses that detects its surroundings and speaks up at critical moments, such as when a car is approaching. That kind of split-second assistance could be transformative for people with low vision, but today’s visual AI assistants often miss those moments.
The problem isn’t that the technology can’t detect its environment. It’s that current AI systems get bogged down trying to analyze every single frame of video, dozens per second, slowing themselves down in the process. By the time they recognize what’s happening, the moment for helpful intervention has passed.
Now, researchers from Microsoft Research Asia and Nanjing University have designed a system aimed at overcoming this limitation. Their model, called StreamMind, processes video more like a human brain, skimming over uneventful moments and focusing only when something important occurs. The result is video processing that’s up to ten times faster, quick enough to respond as events unfold.
A brain-inspired approach
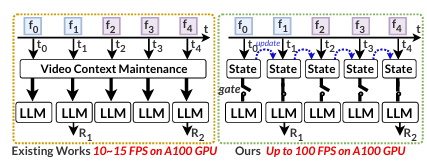
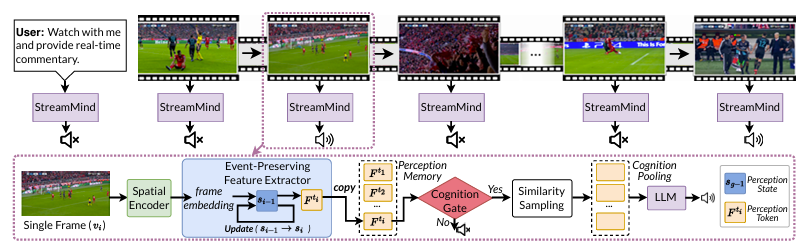
The key insight is surprisingly simple: instead of analyzing every frame, StreamMind uses an event-gated network that separates fast perception from deeper analysis (Figure 1).
A lightweight system continuously scans video for changes. Only when something meaningful occurs, like a car entering a crosswalk, does it trigger a more powerful large language model (LLM). This decoupling lets the perception module run at video speed, while the cognition module, the LLM, activates only when needed. By removing unneeded computation, StreamMind can keep pace with the video stream, maintaining real-time awareness of its environment.
Demonstrations: StreamMind in action
In demonstrations, StreamMind provides responses that match the timing of the event, while current methods lagged. It kept pace with a soccer match, providing smooth play‑by‑play commentary, and guided a cook through a recipe step by step.
How the technology works
StreamMind combines two key innovations to enable real-time video perception and response:
Smart memory system
The Event Perception Feature Extractor (EPFE) addresses the biggest bottleneck in current video AI models: how to handle incoming frames in real time without getting overwhelmed. It uses a state‑space model—a method for tracking how data streams (such as video, audio, or sensor inputs) change over time—to extract patterns from long, continuous input. This allows the EPFE to remember key events using just one compact piece of information, called a perception token, and enables the system to efficiently keep pace with the video stream.
Intelligent decision making
The second component determines whether what’s occurring in the video is relevant to the user’s request and whether the assistant should respond. This is a challenge because often there’s no direct connection between a user’s request and individual video frames. For example, a request like “help me fix my bike” requires understanding when to jump in with assistance.
To make those judgments, StreamMind draws on knowledge from an LLM to recognize when events are relevant and a response is needed. A small gating network, combined with a compact one-token summary of the video input, allows StreamMind to monitor events in real time and autonomously call on the LLM when it is time to act.
Testing shows major speed gains
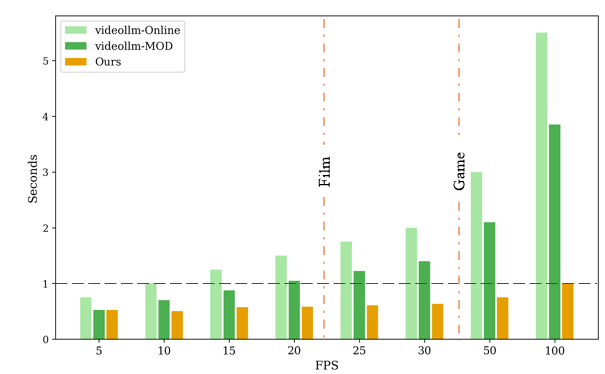
When evaluated against existing methods, StreamMind’s processing speed surpassed all other systems at every tested video speed. Even for fast 100-fps gaming video streams, it kept up with every frame in real time, something no previous system could manage (Figure 3).
The researchers tested StreamMind in a range of scenarios, including online video commentary, predicting what would happen next in a video, and recognizing complex tasks like changing a tire or cooking. They used large datasets such as Ego4D (3,670 hours of first-person video from 923 participants across 74 locations), SoccerNet (videos of 12 European soccer matches), and COIN (11,827 instructional videos across 12 different subjects). The following tables show the detailed results of these tests.
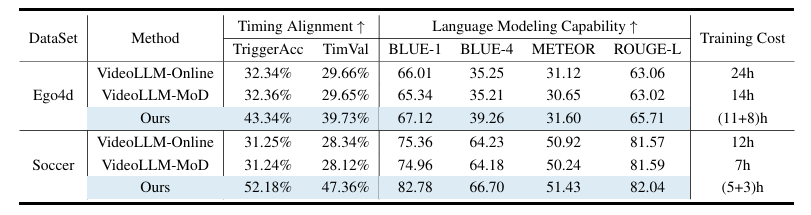
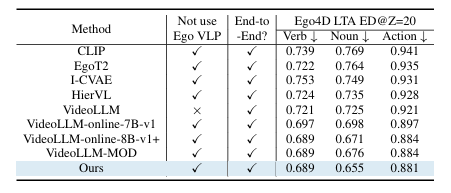
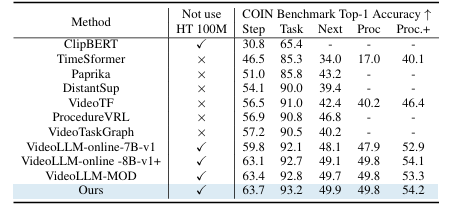
Across all tests comparing SteamMind’s timing alignment and language modeling capabilities to those of existing streaming dialogue models, StreamMind delivered the best results, demonstrating that it can handle complex, fast-changing, real-world scenarios.
From lab to real life
StreamMind’s event-driven design could make wearable AI systems more responsive, allowing smart glasses and similar devices to react to important events as they happen rather than after the fact. By focusing on the moments that matter, rather than every frame, it could make smart glasses and similar devices far more responsive—able to guide, warn, and assist in step with real-world events.