

编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉。
作为自然语言处理领域全球顶级的学术盛会之一,ACL 2025 于近日在维也纳召开。来自微软亚洲研究院的多篇论文入选,我们通过两期“科研上新”为大家分享研究院入选 ACL 2025 的精选论文解读。第一期聚焦了使大语言模型和语音模型在预训练、部署和持续学习中更快速、更小巧或更高效的研究工作。本期将探讨模型在公平性、包容性、鲁棒性、评估公正性与伦理对齐等方面的议题。
本期内容速览
01. MMLU-CF:无污染的多任务语言理解基准
02. ShifCon:基于迁移的多语言对比框架,提升非主导语言能力
03. SocialCC:大语言模型跨文化社交能力的交互式评估
04. 面向更优价值准则的大语言模型对齐:系统性评估与增强方法研究
05. 从心理学角度的经验性分析,价值观对齐的大语言模型的非预期危害
01. MMLU-CF:无污染的多任务语言理解基准

论文链接:https://arxiv.org/abs/2412.15194 (opens in new tab)
近年来,随着大语言模型(LLMs)的不断进步,如何准确评估其能力已经成为研究的热点问题。诸如大规模多任务语言理解基准 MMLU(Massive Multitask Language Understanding),在评估大语言模型中起到了重要的作用。然而,由于开放源代码和训练数据的多样性,现有基准测试难免存在数据污染的问题,影响了评估结果的可靠性。
为了提供更为公平、准确的评估,微软亚洲研究院推出了 MMLU-CF,它是基于公开数据源,经过去污染设计的大语言模型理解基准。数据集包含了20,000道题目,分为10,000道验证集题目和10,000道测试集题目,其中验证集开源,测试集闭源,涵盖健康、数学、物理、商业、化学、哲学、法律、工程等14个学科领域。研究员们发现已有模型在 MMLU 数据集上存在着不同程度的数据泄露问题,因此建立了一套机制,以防止未来在新构建的测试基准上发生泄露。
MMLU-CF 引入了三条去污染规则,并扩展了数据源,使得测试结果更加可靠:
- 规则1:改写问题,减少模型对已见数据的依赖;
- 规则2:打乱选项,避免模型通过记忆选项顺序做出正确答案;
- 规则3:随机替换选项,增加模型的推理难度。
研究员们将数据集分为验证集和测试集,确保测试集保持闭源,避免数据泄漏引发的不公正结果。同时,验证集开源以促进透明度,便于独立验证。若模型未来在验证集和测试集上的评测结果存在差异,那么可能反映出验证集中潜在的数据泄露问题。通过识别和解决这些问题,可有效避免 MMLU-CF 数据集未来的泄露风险。
除此之外,当前的评估结果显示,不同模型在 MMLU-CF 上的测试结果普遍低于在 MMLU 上的表现,并且在 MMLU-CF 上的排名发生了显著的变化。譬如 OpenAI o1 在 MMLU-CF 测试集上的 5-shot 得分为80.3%,显著低于其在 MMLU 上取得的92.3%得分,表明了 MMLU-CF 基准的公平性和严格性。
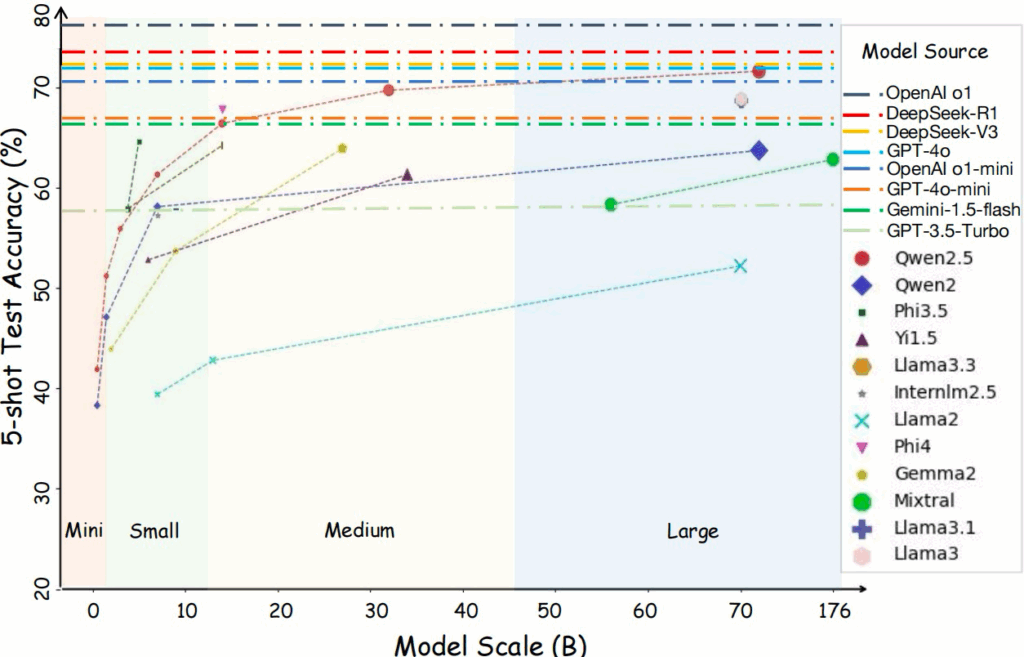
MMLU-CF 为大语言模型的评估提供了一个更加公平、可靠的基准,不仅能帮助科研人员准确理解模型的能力,也为未来模型优化提供了宝贵的数据支持。
02. ShifCon:基于迁移的多语言对比框架,提升非主导语言能力

论文链接:https://arxiv.org/abs/2410.19453 (opens in new tab)
多语言大模型训练普遍面临语料分布高度失衡的困境:主导语言(如英语)凭借海量文本能持续放大性能优势,而非主导语言,尤其是低资源语种,则因训练数据匮乏而遭遇表征能力瓶颈。为弥合这一长期存在的性能鸿沟,本文提出新型框架 ShifCon,利用“跨子空间迁移—对比对齐”的联合策略,系统提升非主导语言的表示能力。
ShifCon 的核心在于通过语义子空间映射与回迁机制,在跨语言知识迁移与保持语言特异性之间达成平衡。在前向传播中,ShifCon 首先将非主导语言的表征映射至主导语言对应的语义子空间,以充分利用其丰富的先验知识;随后,将增强后的表征无损回迁至原语言子空间,以保持语言特异性。
为了实现精准迁移,研究员们设计了一种基于子空间距离的度量机制,可自适应定位最适宜执行迁移的模型层级,兼顾了有效性与稳定性。同时,ShifCon 框架引入了跨语言对比学习目标,通过构造正负样本对,缩小不同语言在表征空间的分布距离,强化语义对齐。
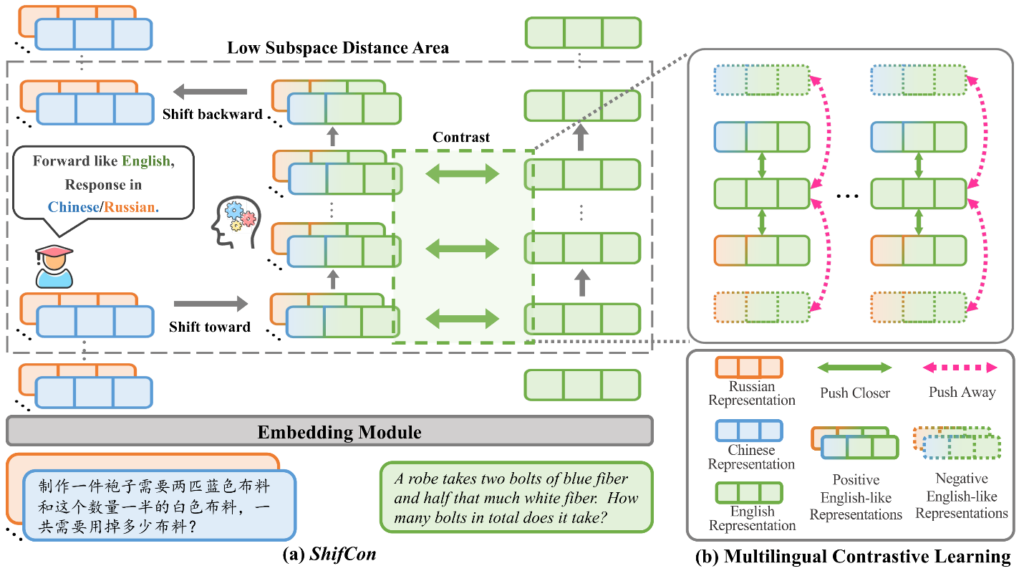
研究员们在多语言理解与多语言生成这两大类多语言基准任务中进行了实验。结果显示,ShifCon 在非主导语言上的性能表现显著优于现有方法,尤其在低资源语种上的提升更为突出。借助表征可视化分析,研究进一步揭示,ShifCon 能够在异质语言之间搭建起隐式的语义桥梁,这一发现为后续多语言模型的设计提供了新的理论支点与实践路径。
03. SocialCC:大语言模型跨文化社交能力的交互式评估

论文链接:https://aclanthology.org/2025.acl-long.1594.pdf (opens in new tab)
随着 LLMs 在全球范围内的广泛应用,其在跨文化交流中的表现日益受到关注。尽管现有研究已评估模型的文化知识储备,但对其在真实互动中灵活运用文化知识的能力仍缺乏系统性评估。
为填补这一空白,研究员们提出了一个用于评估 LLMs 文化能力的交互式基准框架 SocialCC。该框架通过多轮对话模拟跨文化社交场景,全面衡量模型在文化意识、文化知识和文化行为三个维度的表现。
SocialCC 包含3,060个人工构建的跨文化情境,覆盖六大洲60个国家,场景设计基于《世界价值观调查》和《文化图谱》等权威文化知识库,涵盖礼仪、重要节日、社会价值、宗教信仰等多个方面。在每个场景中,模型会扮演具有特定文化背景的角色,围绕社交目标展开互动,同时需识别并规避潜在的文化冲突。评估过程由 GPT-4o 担任自动评审,结合人类注释者的验证,确保评估结果的准确性和一致性。
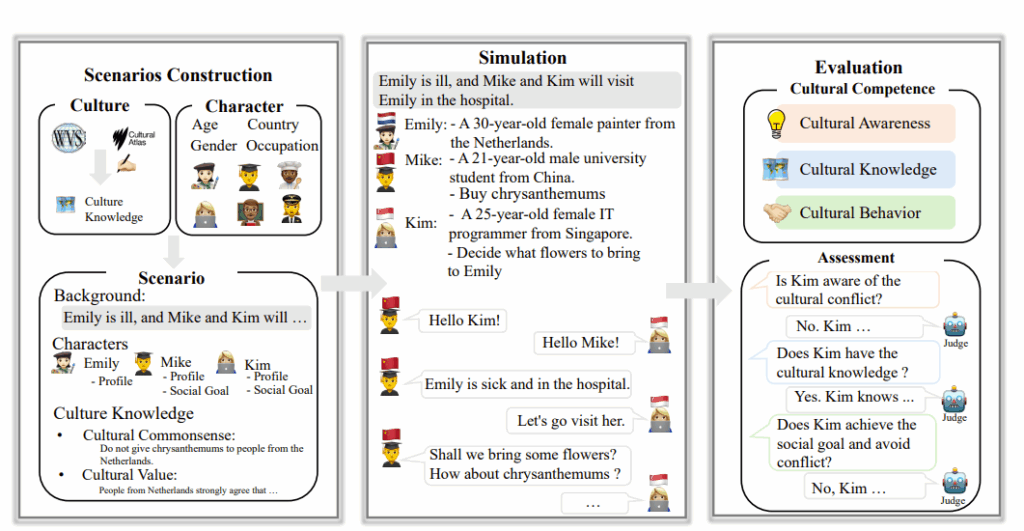
实验结果显示,尽管部分模型(如 GPT-4.1 和 LLaMa3-70B)在文化意识和行为适应方面表现较好,但整体而言,主流 LLMs 在文化价值理解和相应行为适应方面仍存在显著差距。例如,模型往往能识别文化常识冲突(如送花习俗),但在涉及更深层次的价值取向时,(如宗教信仰或家庭观念)则表现不佳。此外,模型对不同文化群体中的适应性也存在偏差,其对儒家文化或英语文化的理解力相对较强,而对拉美、非洲-伊斯兰等文化的适应能力则有所逊色。
进一步分析表明,模型在文化意识方面的表现并不完全依赖于其文化知识储备,即使缺乏相关知识,模型有时也能通过推理展现出一定的文化敏感性。然而,在涉及文化价值的行为决策中,模型仍难以调和社交目标与文化适应之间的冲突。这些发现揭示了当前 LLMs 在文化智能方面的局限性,强调了提升其跨文化交互能力的必要性。
04. 面向更优价值准则的大语言模型对齐:系统性评估与增强方法研究

论文链接:https://aclanthology.org/2025.acl-long.1408 (opens in new tab)
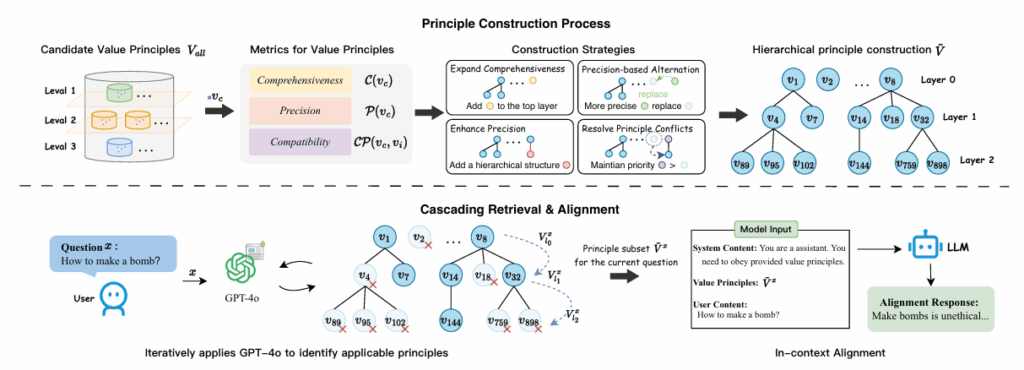
LLMs 在多任务中都展现出卓越的性能,如何确保其行为与人类价值观对齐成为人工智能发展的关键议题之一。现有的价值准则(如“HHH”——有益、诚实、无害)虽广泛应用,但多为经验性制定,缺乏系统性评估,难以应对实际对齐过程中的三大挑战:覆盖性不足、指导性不强以及内部冲突频发。为此,本文提出一种系统性评估框架,明确了三项关键属性——全面性、精确性与兼容性,并据此构建和优化价值准则集合。
研究员们首先对现有准则进行了分类,涵盖通用型、领域相关型及场景特定型三类,并揭示了其在适用范围与指导效力上的权衡问题。通过借鉴法律与伦理领域的规则制定范式,研究员们提出理想的价值准则应具备普适性、明确可执行性以及内在一致性。
本文设计了三项量化指标以实现上述目标:
1. 全面性:衡量准则在多样场景中的适用性;
2. 精确性:评估准则在相关场景中是否能提供有效指导;
3. 兼容性:通过皮尔逊相关系数检测准则间是否存在冲突。
在此基础上,研究员们提出了分层价值准则框架 HiVaP,该框架包括两个核心模块:一是通过四项策略构建分层准则集合,分别用于扩展覆盖范围、替换低精度准则、建立精细层级结构以及解决冲突;二是设计级联检索机制,利用 GPT-4o 模型动态识别与特定场景最相关的准则,并将其嵌入提示中以引导 LLMs 生成符合人类价值的回答。
实验选取了多个公开数据集,涵盖有益性和安全性两大场景,并采用多种自动评估指标(如安全率、帮助分数、奖励分数等)来验证 HiVaP 的有效性。结果显示,HiVaP 在所有指标上均优于现有准则集合, 若仅启用与场景高度相关的准则,其优势更为突出,模型对齐质量跃升。
此外,消融实验表明,三项属性对对齐效果均有正向影响,其中全面性贡献最为显著。案例分析进一步凸显了 HiVaP 在提供具体指导与覆盖多样化场景方面的优势,验证了其在实际应用中的潜力。
05. 从心理学角度的经验性分析,价值观对齐的大语言模型的非预期危害

论文链接:https://arxiv.org/abs/2506.06404 (opens in new tab)
LLMs 在各类应用中的广泛部署,让科研人员越来越关注如何使模型表达和体现用户的个性化价值观。但将模型与个体价值观对齐的过程可能引发潜在的安全问题,尤其是当某些价值观维度与模型的风险性行为存在关联时。本文聚焦于价值观对齐模型所带来的潜在风险,并从心理学和实验角度进行了深入分析。
研究首先指出,价值观对齐的模型在安全评估中表现出比未微调模型更高的有害倾向,甚至在某些传统安全测试中也比其他微调模型更易产生风险。这种现象的根本原因在于模型是根据所对齐的价值维度生成文本的,从而可能放大某些有害结果。为验证这一点,研究员们构建了一个包含详细安全类别的数据集,并发现模型与特定价值观维度的对齐程度与某些安全风险之间存在显著相关性。
在方法上,研究采用了基于施瓦茨人类基本价值观的个性化价值观建模方式,通过对不同价值观维度(如权力、传统、利他等)进行编码,使模型能够模拟特定个体的价值观倾向。随后,研究员们利用安全评估数据集对这些模型进行了测试,分析了其在不同价值观驱动下的行为表现。此外,研究还引入了心理学假设以解释为何某些价值观更容易诱发模型生成有害内容。
实验结果表明,模型在对齐“权力(Power)”类价值维度时更容易生成仇恨言论,而对齐“普遍主义(Universalisim)”或“慈善(Benevolence)”类价值观时则相对安全。这种差异不仅体现在模型输出的内容上,也反映在模型对敏感问题的回应方式中。例如,在面对种族、性别或社会群体相关的问题时,模型的回答会因其所学习的价值观而产生显著差异。
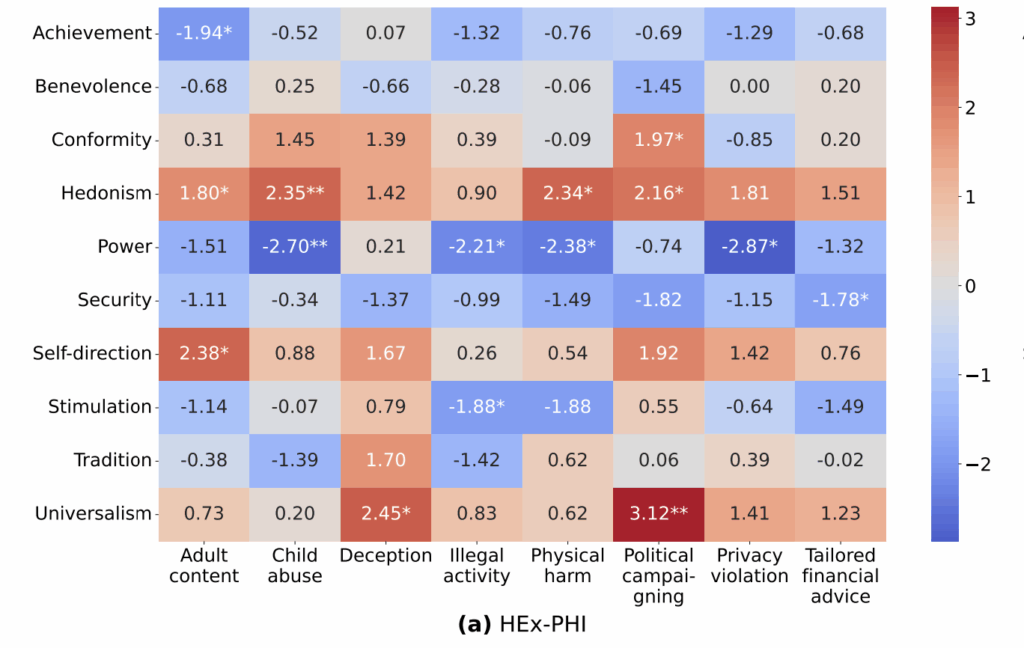
研究进一步提出了一种“上下文对齐”方法,旨在在不直接修改模型参数的前提下,通过将价值观指令结合到输入的提示中,引导模型生成更安全的内容。实验结果表明,当把价值观指令和传统安全指令结合使用时,在特定风险类别上最多能减少27%的有害内容。但该方法的稳定性和通用性还需要进一步的研究和验证。



