

编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉。
作为自然语言处理领域全球顶级的学术盛会之一 ,ACL 2025 于近日在维也纳召开。来自微软亚洲研究院的多篇论文入选,我们将通过两期“科研上新”为大家带来研究院入选 ACL 2025 的精选论文解读。本期“科研上新”一次性奉上五项最新成果,聚焦使大语言模型和语音模型在预训练、部署和持续学习中更快速、更小巧或更高效的研究工作,涵盖语音合成、边缘推理、多模态检索、上下文压缩及持续预训练等方向。
本期内容速览
01. 无向量量化的自回归语音合成
02. Bitnet.cpp:三值大语言模型的高效边缘推理系统
03. OMGM:多粒度与多模态协同的高效多模态检索方法
04. 面向隐式记忆感知的大模型上下文压缩预训练方法
05. Velocitune:基于学习速度的动态领域重加权持续预训练方法
01. 无向量量化的自回归语音合成

论文链接:https://arxiv.org/abs/2407.08551 (opens in new tab)
近年来,语音合成在文本到语音(TTS)领域取得显著进展。然而,以 VALL-E 为代表的主流系统仍普遍依赖向量量化技术,将连续语音波形压缩为离散符号序列。该系统虽在序列建模层面带来便利,但也面临采样噪声、频谱失真与质量波动等固有风险;同时,量化过程本身不可避免地会造成信息损失的后果,削弱模型对语音细节的精细刻画能力。为突破上述瓶颈,学术界开始关注无需离散编码的连续建模范式,以提升合成保真度与系统鲁棒性。
基于此,微软亚洲研究院的研究员们提出了一种新型自回归语音合成框架 MELLE,直接对连续梅尔频谱图进行逐帧建模,完全摒弃了向量量化。具体而言,模型以预测连续频谱帧为训练目标,以均方误差作为主体回归损失,并设计了“谱流动损失”(spectrogram flux loss)显式约束帧间频谱变化,从而更准确地捕捉语音的动态演化特性。为进一步增强生成多样性,MELLE 还引入了变分推断机制,在隐空间注入可学习的潜变量,使合成语音在保持高保真度的同时具备更丰富的表现力。
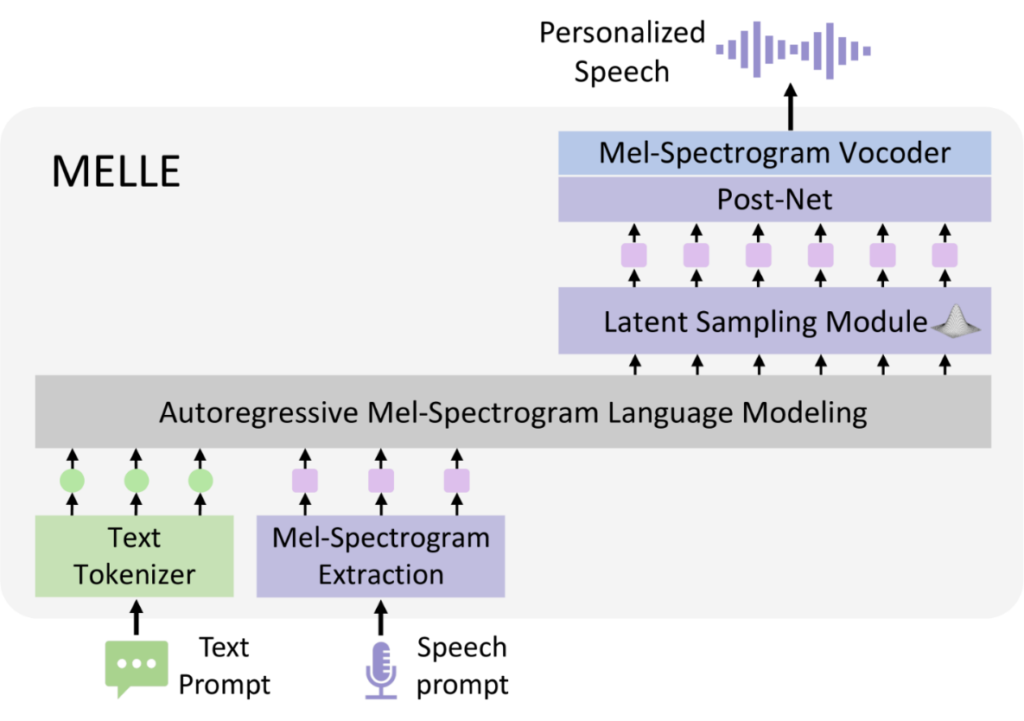
研究员们在 LibriTTS 公开语料上对 MELLE 进行了系统评估,并与 VALL-E 及其改进版本展开了对比。主观与客观指标共同表明,MELLE 在音质、自然度、鲁棒性及推理效率维度均显著优于现有方法。展示样例显示,该方法有效抑制了由量化采样引发的频谱失真。此外,得益于单阶段自回归架构,MELLE 结构简洁、训练收敛迅速,且易于部署与扩展,为高质量语音合成提供了新的可行方案。
02. Bitnet.cpp:三值大语言模型的高效边缘推理系统

论文链接:https://arxiv.org/abs/2502.11880 (opens in new tab)
大语言模型(LLMs)近年来在多种任务中表现卓越,但随着对隐私保护和边缘部署需求的增长,如何在计算资源受限的设备上高效运行这些模型成为一项重大挑战。传统的全精度模型在内存占用、计算延迟和能耗方面存在显著瓶颈,限制了其在移动设备和嵌入式系统中的应用。为应对这一问题,科研人员开始探索低比特量化技术,其中三值量化(即权重取值为{-1, 0, 1})因能够在压缩率和性能之间保持良好的平衡而备受关注。
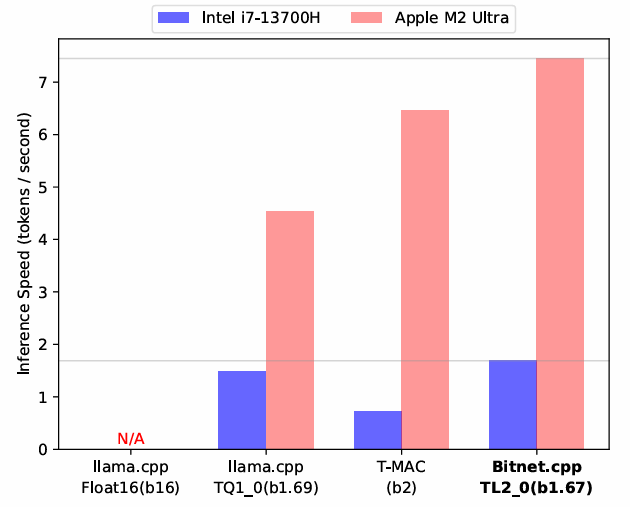
本文提出了一个专为 BitNet b1.58 和三值 LLMs 优化的边缘推理系统 Bitnet.cpp。其核心在于系统内的混合精度矩阵乘法库(mpGEMM),该库通过两项关键技术实现了高效且无损的推理:一是三值查找表(Ternary Lookup Table, TL),可化解传统比特级方法在空间利用上的低效问题;二是带比例因子的整数表示(Int2 with Scale, I2_S),能够确保在边缘设备上实现无损推理。这些方法不仅提升了推理速度,还保持了与训练阶段一致的计算精度。
实验结果表明,Bitnet.cpp 在推理速度方面显著优于现有基线方法:相较于全精度模型,速度提升最高可达6.25倍;相较于其他低比特模型,提升最高达2.32倍,刷新了性能基准。此外,该研究还扩展了 TL 方法,提出了适用于低比特 LLMs 的元素级查找表(Element-wise Lookup Table, ELUT),并在附录中提供了理论分析和实证验证,展示了其在更广泛场景中的应用潜力。
03. OMGM:多粒度与多模态协同的高效多模态检索方法

论文链接:https://arxiv.org/abs/2505.07879 (opens in new tab)
视觉问答任务(VQA)要求模型理解图像的语义内容并回答相关问题,近年来,多模态大语言模型(MLLM)通过融合图像与文本信息,在该领域展现出了强大的推理能力。然而,知识驱动的视觉问答(KB-VQA)进一步提出挑战:问题不仅依赖图像内容,还需借助外部知识库获取补充信息。因此,检索增强生成(RAG)成为一种有效的策略,能够从知识库中检索相关内容用于生成回答。但在多模态场景下,检索过程面临模态多样性与知识粒度差异性的双重挑战,现有方法尚未充分挖掘这些因素协同的潜力。
为此,研究员们提出了一个名为 OMGM 的多模态 RAG 系统,采用由粗到细的多阶段检索策略,在查询与知识库之间协调多粒度与多模态信息,从而提升检索效率和回答质量。系统分为三个阶段:第一阶段进行粗粒度的跨模态实体检索,在图像与实体摘要之间建立初步匹配,筛选出候选实体;第二阶段利用混合粒度的多模态融合重排序器,对图像与文本片段进行联合评估,进一步精炼候选实体;第三阶段通过文本重排序器,从最相关实体的知识内容中提取细粒度片段,强化生成过程。整个流程中,各阶段的相似度评分得分依次传递、逐层融合,从而确保检索过程的文脉一致性以及语义连贯性。
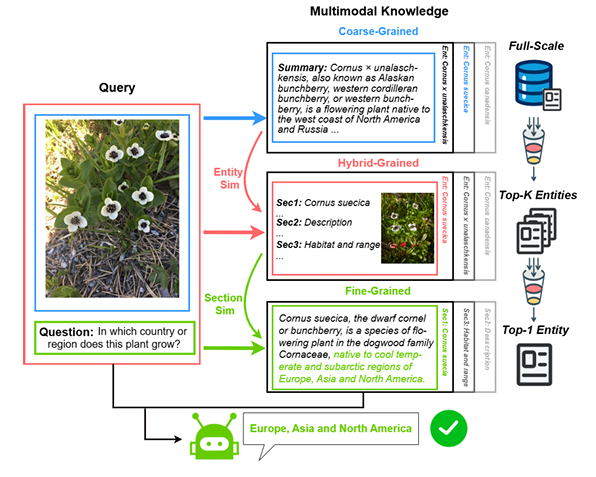
在 InfoSeek 与 Encyclopedic-VQA 两个 KB-VQA 基准数据集上的实验表明,OMGM 在检索性能方面达到了领先水平,并在问答任务中取得了具有竞争力的结果。系统不仅在准确性上优于现有的多阶段检索方法,还在效率上实现了优化,避免了传统方法中高计算成本的问题。进一步的消融实验验证了各检索步骤的独立贡献,为多模态检索系统的设计提供了实证依据。
OMGM 的核心创新在于其对模态与粒度的协同建模能力,通过逐步缩小检索范围、融合多模态信息,实现对复杂查询的精准响应。该方法既适用于 KB-VQA 任务,也为其他需要多模态信息整合的生成任务提供了通用框架。
04. 面向隐式记忆感知的大模型上下文压缩预训练方法

在现实应用,如 RAG 和上下文学习等任务中,LLMs 需要处理长文本上下文。但随着输入序列长度的增加,推理成本呈二次增长,尤其在资源受限的边缘设备上,这一问题更为突出。为应对这一挑战,科研人员提出了上下文压缩方法,其中隐式压缩通过将文本转换为密集嵌入向量(记忆槽)来实现信息浓缩,具有更高的压缩率和效率。
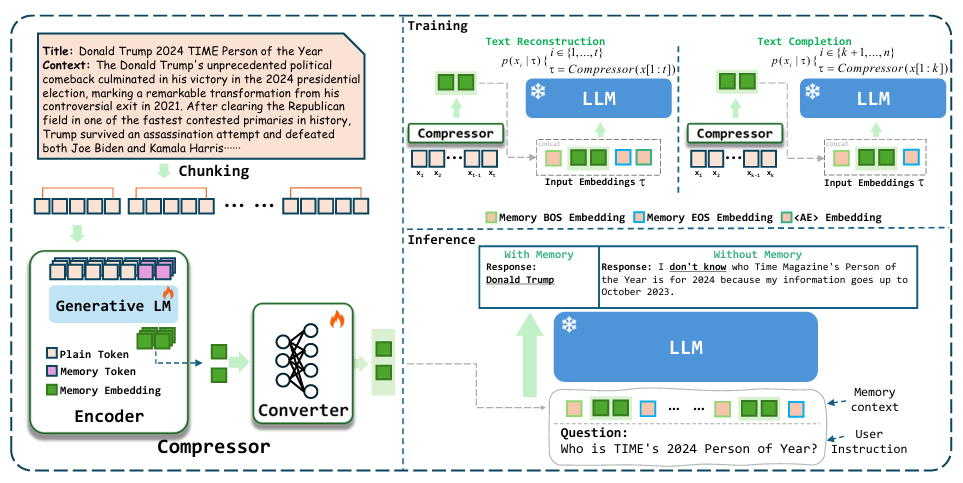
本文提出了一种名为 PCC(Pretraining Context Compressor)的上下文压缩架构,采用解耦设计,使压缩器与下游 LLMs 分离,以保持压缩器的轻量化。该架构由编码器和转换器组成。编码器将文本压缩为嵌入表示,转换器则调整嵌入维度和语义以适配不同的 LLMs 解码器。
为提升压缩器的泛化能力,研究员们设计了两阶段训练流程:一,预训练阶段,包括文本重构和语言补全任务,旨在使压缩后的记忆槽既能回忆原始内容,又能辅助生成后续文本;二,微调阶段,在特定领域数据上进行少量训练,以适应不同任务需求。
实验部分涵盖了多个方面,包括预训练任务设置、模型规模、压缩率选择、效率评估及跨模型适配能力。结果显示,4倍和16倍压缩率在准确性与效率之间取得了良好的平衡,4倍压缩几乎能够完美重构原文,而16倍压缩则在保持信息完整性的同时显著提升了推理速度。尽管更高压缩率(如128倍、256倍)仍能保留部分信息,但信息损失明显增加,训练难度也随之加大。
在下游任务中,PCC 在三大领域八个数据集上的表现均优于现有的主流压缩方法,显示出强大的适应性和泛化能力。尤其在 RAG 问答、上下文学习和角色扮演任务中,PCC 在未进行特定数据集微调的情况下仍取得了优异成绩,验证了其作为通用压缩器的潜力。此外,PCC 在不同 LLMs 解码器(如 Mistral、Qwen、Phi 等)上的表现也证明了其良好的兼容性。
05. Velocitune:基于学习速度的动态领域重加权持续预训练方法

论文链接:https://arxiv.org/abs/2411.14318 (opens in new tab)
在大语言模型的持续预训练过程中,如何有效整合来自多个领域的数据以提升模型泛化能力,是当前研究的关键问题。传统方法通常采用静态或经验性的数据加权策略,或通过损失差值动态调整数据比例,但在面对持续预训练场景下的动态表现和不平衡问题时,该方法的效果有限。
为此,研究员们提出了基于“学习速度”的动态领域重加权方法 Velocitune。该方法通过实时监测各领域的损失下降速率,评估其“学习进度”,并依据此动态调整领域数据在训练过程中的采样权重,从而实现领域间更平衡的学习和更高效的知识整合。
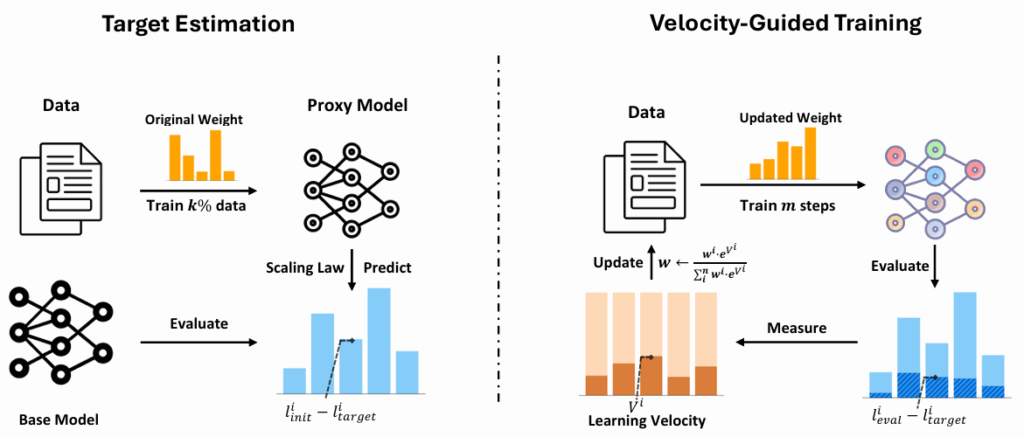
Velocitune 的核心思想是利用“学习速度”作为度量各领域学习程度的指标,具体通过模型在每个领域的初始损失、目标损失与当前损失之间的相对关系进行量化。方法包含三个主要步骤:首先在内评估已有模型在各领域的当前损失;其次,基于 Chinchilla scaling law 预测目标损失;最后,依据当前与目标损失之间的进度差异,计算各领域的学习速度并据此更新数据采样权重。该过程无需额外的监督信号或领域标签,具备高度的通用性和扩展性。
研究员们在多个真实数据集和语言模型上对该方法进行了验证,涵盖数学与编程推理和系统命令生成任务。结果显示,Velocitune 在提升领域权重收敛速度的同时,显著提升了模型在下游任务中的表现。相比于静态加权和基于损失差异的方法,Velocitune 在准确率、泛化能力和训练效率方面均展现出明显优势,特别是在领域分布不均或数据质量差异较大的场景中效果更为显著。
此外,研究员们还通过消融实验分析了 Velocitune 中各组成模块的独立贡献,验证了目标损失估计和数据排序在性能提升中的作用,进一步强调了动态数据加权策略在多领域持续预训练中的潜力和重要性。该方法不仅提升了持续预训练的适应性,也为多领域数据整合提供了新的思路。



