

编者按:当前,大语言模型在代码生成领域已展现出惊人的能力,但能否胜任真实软件开发中的“新增功能实现”任务,仍是一个关键未解的问题。对此,微软亚洲研究院与北京大学联合发布了首个专注于仓库级新功能实现的基准测试 FEA-Bench,填补了评估体系中的重要空白。该测试集构建于真实开源项目的 pull request (合并请求),覆盖1400多个高质量任务,系统评估了主流大模型在复杂工程任务中的表现。FEA-Bench 不仅为推动代码生成系统迈向真实世界的新功能实现任务提供了坚实支撑,也为相关研究拓展了更广阔的探索空间。
随着人工智能的快速发展,大语言模型在代码生成领域展现出越来越多的可能性,从函数级别的补全到复杂问题的修复,AI 已逐渐渗透至开发者的工作流程。然而,在真实的软件工程场景中,大语言模型是否具备实现新功能的能力,仍是一个亟待验证的重要课题。与此同时,现有的基准测试多聚焦于大模型的独立编程问题或修复任务,缺乏对“新功能实现”这一核心能力的系统性评估。
对此,来自微软亚洲研究院与北京大学的研究团队联合推出了首个面向仓库级新功能实现的基准测试 FEA-Bench,填补了当前代码生成评估体系中的关键一环。该基准测试通过1401个高质量任务实例,全面评估了大语言模型在新增功能时所需的代码生成与编辑能力,揭示了当前模型在复杂软件工程任务中的局限性,为未来的研究提供了重要方向。
FEA-Bench推动大语言模型走向真正的软件工程自动化
尽管当前的大语言模型如 GPT-4、DeepSeek-Coder 和 Qwen2.5-Coder 等在代码补全、函数级生成乃至修复 GitHub 议题(issue)等任务中表现出色,但在实际的软件开发中,为代码仓库增添新功能是一个更重要且难度更大的需求。开发者往往需要在已有代码库中添加新组件(如函数、类),并相应修改其他相关代码以确保整体的一致性。这种仓库级增量开发能力是衡量大语言模型能否胜任真实软件工程任务的核心指标。而且,目前尚无专门针对该能力设计的评估基准。
FEA-Bench 的出现填补了这一空白。该数据集基于83个开源 Python 项目的真实 pull request (合并请求)数据构建而成,包含1401个新增功能的任务实例,并配套完整的单元测试验证机制,从而保证生成结果的可执行性与准确性。每个任务实例均要求模型不仅要生成新的代码组件,还需理解整个仓库结构并在必要时进行联动修改,从而实现端到端的功能实现。
不同于以往主要关注 bug 修复(如 SWE-bench)或独立编程(如 HumanEval)任务的基准测试,FEA-Bench 将目标聚焦于新功能的实现。其任务实例全部来自真实的 GitHub pull request,涵盖多个行业场景,具有较高的代表性和实用价值。这样的设计不仅使数据集更贴近真实的软件开发情境,也为大模型在工业场景中的落地提供了指导意义。
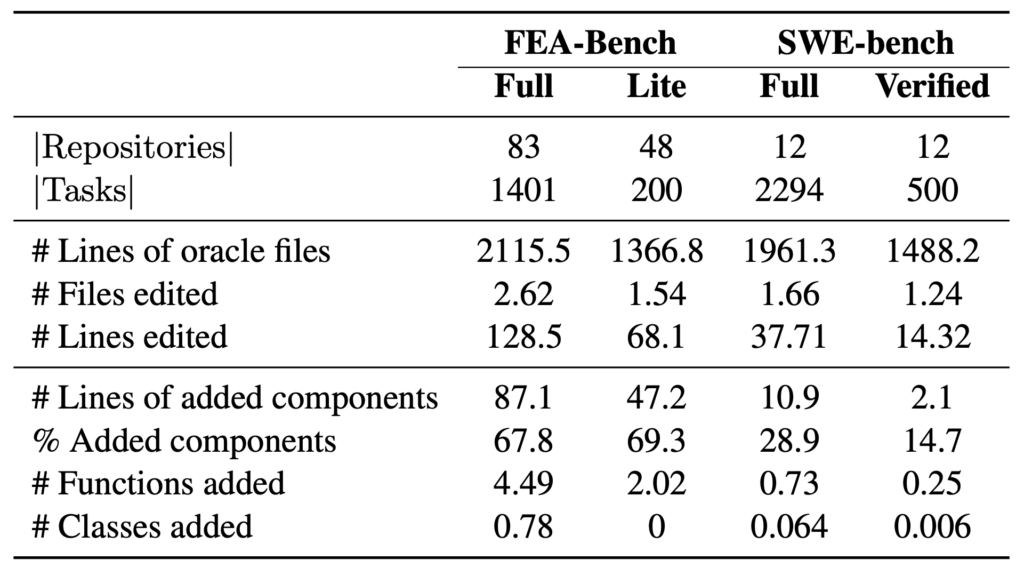
为了确保任务设置的真实性与挑战性,FEA-Bench 构建了一套多维度的难度控制与质量保障机制。在数据筛选阶段,系统会结合规则过滤与意图识别技术,精准甄别出确实涉及新功能开发的 pull request。每个任务实例均配备详尽的功能请求描述、新增组件定义(包括函数签名、类结构等)、环境配置信息及单元测试用例,并标注黄金补丁(gold patch)作为参考实现。所有实例在发布前均通过自动单元测试验证,确保数据集具有良好的可验证性和可复现性,为评估模型性能提供了稳定可靠的基础。

此外,FEA-Bench 还提供了一个轻量版本 FEA-Bench Lite,用于适配不同实验条件下的计算资源需求。该子集在保留代表性的前提下,筛选出了复杂度相对较低的任务实例,方便科研人员在资源受限的环境中进行模型的快速迭代与评估。
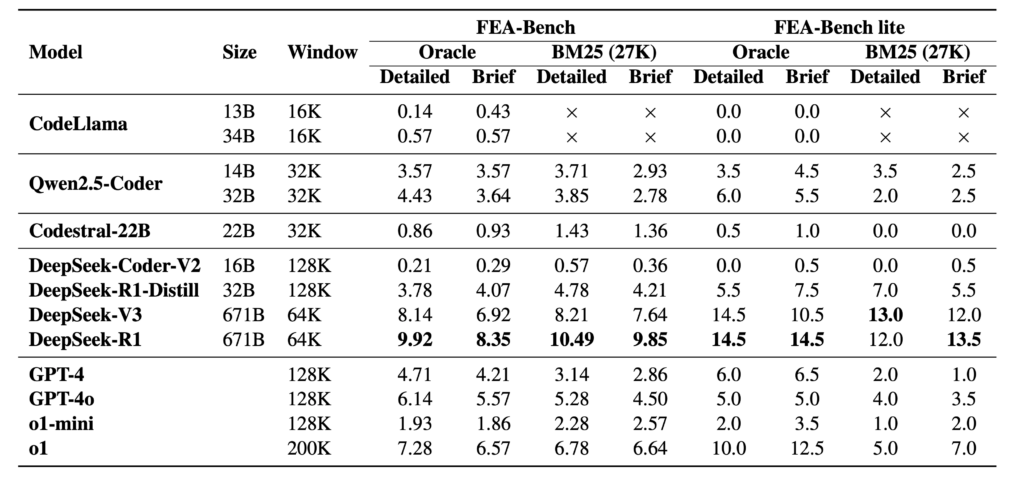
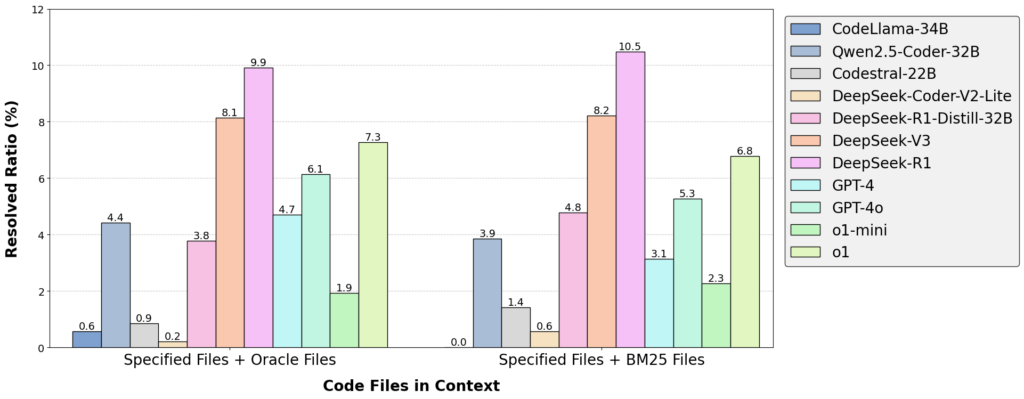
研究团队使用 FEA-Bench 系统地评估了 GPT-4、DeepSeek-R1、Qwen2.5-Coder 等目前主流的大语言模型。结果显示,在不使用代理(agent)框架的情况下,当前最优模型 DeepSeek-R1 在 Oracle 设置中(给定需要编辑的代码文件作为上下文输入)的解决率仅为9.92%。相比之下,SWE-bench 中模型的 bug 修复成功率普遍在30%以上。这一差距充分说明,“新增功能”任务在逻辑复杂度、跨文件一致性维护与逻辑整合等方面,都对大语言模型提出了更高的要求。
开启新阶段:助力AI真正理解软件工程
FEA-Bench 的发布为代码生成研究打开了一个全新的维度。在为学术界提供全新的测试平台的同时,FEA-Bench 也为工业界评估 AI 辅助开发软件新功能提供依据标准。研究团队希望通过 FEA-Bench,可以让更多人关注 AI 在面对自由度较高的新功能实现中的表现,激发更多科研人员探索如何让 AI 真正理解并深度参与现代软件工程的核心。
未来,研究团队将持续拓展任务的覆盖范围、优化检索机制、提升生成格式的兼容性,进一步推动大语言模型向自主软件开发迈进。



