

编者按:当人工智能遇上创意设计,一场视觉革命正悄然展开。人工智能图像生成技术为人们提供了无限的灵感源泉。然而,从实验室走向实际应用,从激发灵感到完美创作,在编辑自由度和可控性需求日益增长的当下,人工智能生成图像的技术仍然面临诸多挑战。
微软亚洲研究院的研究员们在文本生成图像领域的两项最新研究成果,为促进相关技术的实际应用开辟了新的道路——匿名区域 Transformer (Anonymous Region Transformer, ART) 通过生成多图层,赋予了图像编辑更大的灵活性;DesignDiffusion 则实现了图文一致性的端到端生成,让文字与图像的融合更加自然、精准。相关论文已被 CVPR 2025 接收。
人工智能图像生成技术正在以前所未有的速度重塑着人们的视觉世界。从简单的图像合成到复杂的创意设计,这一技术为视觉艺术注入了新的活力。但目前这些生成结果大多还停留在激发灵感的层面,距离实现直接应用于设计需求还有一定差距,仍需要设计师人工进行大量修改与完善。
当前的文本生成图像模型通常只能一次性生成整张图片,无法对指定的部分进行修改。例如,当生成图像中的某个元素颜色与需求不符时,现有的技术难以在此基础上直接更换颜色或进行二次修改。
当你想要生成一朵朵分散的云时,人工智能可能会生成一团云,而且每次修改都重新生成一整张图,无法单独对云朵进行修改。

此外,设计图往往需要与文字搭配,但人工智能生成带文字的图像时,常常会出现文字错误、文字布局不一致等问题,严重影响了图像的整体质量和实用性。
在如下人工智能生成的图像中,文字有的错误,有的不整齐,还有重复或变为符号的情况。

如何让人工智能文生图更加灵活、更具可编辑性呢?
微软亚洲研究院的研究员们设计了全新的匿名区域 Transformer (Anonymous Region Transformer, ART) 方法,通过生成多个图层,使用户能再次修改特定区域,大大提升了人工智能文生图的可交互性和可编辑性。同时,研究员们还提出了 DesignDiffusion 框架,能够将生成的文本无缝融入图像中,从而实现高质量和一致性的具有文本的图像生成。两项研究成果均已被 CVPR 2025 接收,并在 GitHub 上开源。
ART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
论文链接:https://arxiv.org/abs/2502.18364 (opens in new tab)
开源地址:https://github.com/microsoft/art-msra (opens in new tab)
DesignDiffusion: High-Quality Text-to-Design Image Generation with Diffusion Models
论文链接:https://arxiv.org/abs/2503.01645 (opens in new tab)
开源地址:https://github.com/chairc/Integrated-Design-Diffusion-Model (opens in new tab)
多图层生成:实现AI文生图的编辑“自由”
传统的人工智能图像生成模型,如 Stable Diffusion 和 DALL-E,虽然能生成高质量的图像,但它们大部分只能生成单一的整体图像。这意味着如果用户想要对图像中的某个特定部分进行修改,就必须重新生成整张图片。这不仅耗时,由于重新生成的图像可能与之前完全不同,还可能破坏原有的设计意图。这种局限性在图形设计和数字艺术等领域尤为明显,因为在这些领域中,创作者常需要通过逐层控制来构建和优化复杂的作品。
为了解决这一问题,研究员们提出了一种用于多层透明图像生成的新方法——匿名区域 Transformer (Anonymous Region Transformer, ART)。ART 能够基于全局文本提示和匿名区域布局直接生成可编辑的多层透明图像。通过这种方法,模型可以将图像分解为多个独立的图层,每个图层包含图像的不同部分。用户可以根据需要,单独修改特定图层,而不影响其他部分。

同时,匿名区域布局大大提高了图像生成的灵活性和效率。传统的文本到图像生成的语义布局需要明确指定整个图像的全局提示以及每个区域的位置和区域特定提示。例如,图2左所示,需要指定每一个区域生成的对象为“一片披萨、一个银匙、一盘甜点”。然而,在处理数十个甚至数百个这样的区域时,这种方式会变得非常耗时且依赖人工操作。相比之下,图2右所示的匿名区域布局仅需一组不带任何提示注释的匿名矩形区域即可。
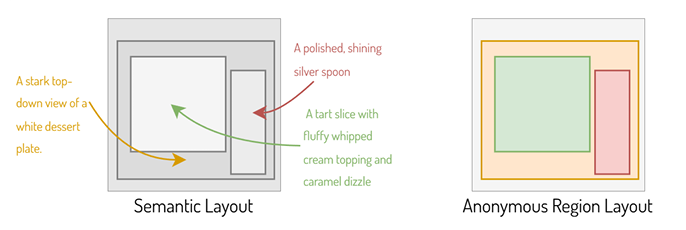
那么,在没有区域特定提示的情况下,匿名区域布局是如何有效发挥作用并保持全局一致性?研究员们发现,这源于 Transformer 模型在文本标记和视觉标记之间的交互,可自主识别每层的语义标签。而且,生成模型在学习过程中捕捉到的类似于图式理论的先验知识,也可以确定不同匿名区域所代表不同的实体元素。由于所有图层都是同时生成的,因此模型能够更好地理解各图层间的关系,从而确保整个图像的视觉一致性和连贯性。

此外,匿名区域布局只关注每个图层中真正有内容的部分,忽略了空白区域。这显著减少了冗余计算,让 ART 可以在短时间内生成包含至少50个图层的复杂图像,同时也意味着模型训练时不再需要人工标注的布局数据,进一步提升了训练效率。
图文一致性生成:让文字“读懂”图像
在平面设计中,文字和图像是两个密不可分的元素。一个优秀的设计作品,文字内容既要精准传达信息,更要与图像内容完美融合,共同构成一个和谐统一的整体。但现有的人工智能图像生成模型在这方面的表现并不理想。比如生成的文字可能存在拼写错误、文字重复、火星文等,又或者在风格和布局上与图像不匹配,使得文字在图像中显得格格不入,破坏了整体的美观度。
针对这些问题,微软亚洲研究院的研究员们提出了 DesignDiffusion 框架,能够根据用户提示,直接合成文本与视觉设计元素。DesignDiffusion 实现了文字与图像的端到端同步生成,确保了文字与图像的一致性,同时通过对文字损失的更强监督,提高了合成视觉文本的质量与准确性。

此前的视觉文本渲染主要有两种方法:一种是在生成图像后修复文本;另一种是在生成图像前,借助大语言模型规划文本区域。这些方法并没有考虑到设计过程中,文本与图像上下文通常相互交织的特性,因此导致渲染出的文本与图像割裂,缺乏一致性。而且,视觉渲染的文字只能模仿文字的形状,并不能理解文字的含义,致使图像中的文字错误频出。
为了解决这些问题,研究员们在 DesignDiffusion 框架中引入了三项关键技术:
- 视觉渲染文本时,必须逐个字母渲染才能保证准确性。然而多数情况下单词是被当作一个整体进行处理,忽略了单词内每个字母的差异,从而导致模型文字生成的错误。研究员们提出对单词进行字母级别的分解法,将提示中的每个字母直接嵌入到潜在扩散模型的 CLIP 文本编码器中。这种集成技术确保了带有视觉文本的设计图像能以更自然、更符合上下文的方式生成。
- 文本的风格、大小和布局上往往各不相同,这极大地增加了模型生成图像时保持一致性的难度。研究员们提出了一种字符定位损失方法,不仅可以确保生成的文字在像素层面的准确性,还能保证其在语义层面的精准度,从而提高文本在图像中放置的适配性。
- 为了进一步增强模型处理设计图像的能力,研究员们还提出了 Self-Play Direct Preference Optimization(SP-DPO) 策略,利用强化学习模拟人类的偏好,通过不断反馈和优化模型,使生成的内容更符合人类的审美标准。
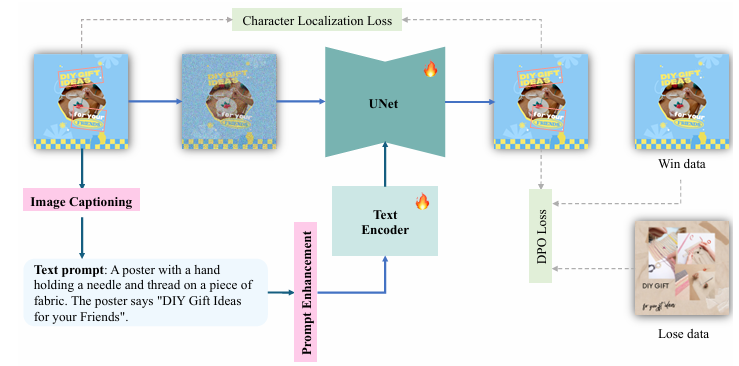
DesignDiffusion 框架摒弃了在生成图像前预先确定文本区域的做法,保留了生成模型的创作自由度。同时,它也能够将生成的文本流畅地融入图像之中,进而创作出可以精准反映输入提示的连贯的设计作品。
AI文生图落地应用:细节问题不容忽视
ART 多图层生成方法和 DesignDiffusion 图文一致性生成框架,解决了当前文生图模型的部分局限性,不仅为科研人员理解和改进文生图模型的控制性和灵活性提供了新思路,也为创意设计领域带来了更多便利,有望在图形设计、数字艺术、动画制作、游戏设计等多个领域发挥积极作用。
“为使这些前沿的研究成果能真正落地并发挥实效,我们正努力将这两项工作整合进现有的设计工具中,以便普通用户也能更加便捷地运用这些技术。此外,我们也已经在 GitHub 上开源了相关成果,希望借此助力推动更多文生图模型和设计软件的进步,让创意设计变得更加简单、高效。”微软亚洲研究院首席研究员陈栋表示。
人工智能在文本到图像生成上已经取得了显著进展,但在实际应用中,细节功能依然不能满足人们的需求,这也恰恰是技术落地中最困难、最急需解决的问题。以图像中的文字生成为例,研究员们下一步计划通过结构化方式来生成文字,包括精确控制字体、大小和样式等。
微软亚洲研究院也期待与设计师、艺术家和创意工作者紧密合作,借助专业视角与实践经验,帮助科研人员更好地了解实际需求和问题,进而研发出更符合用户需求的人工智能生成技术,为创意设计行业带来更多的可能性。
随着人工智能技术的快速发展,确保相关技术能被人们信赖是一个需要攻坚的问题。微软主动采取了一系列措施来预判和降低人工智能技术所带来的风险。微软致力于依照以人为本的伦理原则推进人工智能的发展,早在2018年就发布了“公平、包容、可靠与安全、透明、隐私与保障、负责”六个负责任的人工智能原则(Responsible AI Principles),随后又发布了负责任的人工智能标准(Responsible AI Standards)将各项原则实施落地,并设置了治理架构确保各团队把各项原则和标准落实到日常工作中。微软也持续与全球的研究人员和学术机构合作,不断推进负责任的人工智能的实践和技术。



