

编者按:欢迎阅读“开源上新”栏目!“开源上新”聚焦展示微软亚洲研究院最新发布的开源项目以及开源项目中的重大功能更新。作为“科研上新”的姊妹篇,“开源上新”栏目将帮助你快速了解开源项目的核心价值、关键功能与应用场景,让你能够掌握前沿技术、获取实践案例、提升开发效率,更好地将这些开源项目应用到自己的工作与研究中。
本期我们带来的是微软亚洲研究院全新开源的 Agent Lightning。它开创性地提出了训练-智能体分离式架构,让任何基于大语言模型的智能体几乎无需修改代码,就能接入强化学习(RL)体系,获得持续优化的能力。通过统一数据接口和分层 RL 算法,Agent Lightning 不仅兼容现有主流智能体框架,还能充分利用真实交互数据,推动模型在复杂任务中的稳步进化。这一框架为智能体开发者提供了极大地便利与灵活性,助力推动实现“可训练、可进化”的下一代 AI 智能体。
Agent Lightning 团队正在招聘实习生,详见文末。
在人工智能的浪潮之巅,AI 智能体(AI Agent)正以前所未有的速度重塑着我们与数字世界的交互方式。从自动编写代码、执行复杂指令,到与外部工具和 API 交互,智能体的潜力似乎无穷无尽。然而,每一个开发者和研究者都深知其背后的“成长的烦恼”:尽管基于大语言模型(LLMs)的智能体已经足够强大,但它们依然容易出错,尤其是在面对未经特定训练的真实世界复杂任务时,其性能往往难以满足要求。
如何让这些新兴智能体学会自我提升、持续进化?传统的监督学习需要大量昂贵且难以获取的、带有详细步骤标注的数据。而强化学习(RL)虽然提供了一种通过与环境互动获得奖励信号来学习的强大范式,但现有的 RL 框架与日益多样化、逻辑复杂的智能体开发生态之间存在着巨大的鸿沟。将一个智能体(它可能是用 LangChain 或 AutoGen 等流行框架构建,也可能是用户自己构建)接入现有 RL 系统进行训练,往往意味着繁重、易错的代码改造,甚至会引入训练与部署环境的偏差,费力而不讨好。
另一方面,智能体技术的发展不仅催生了新的应用范式,更开启了一个通过真实世界交互数据反哺和提升基座模型核心能力的新时代。AI 智能体在执行任务时,会产生丰富、复杂的交互数据,这些数据真实地记录了模型在动态环境中进行推理、试错、使用工具和解决问题的全过程。这种数据在规模和多样性上都超过了传统静态数据集,是推动模型能力边界的宝贵经验。
在此背景下,微软亚洲研究院推出并开源了一个灵活、可扩展的开创性框架 Agent Lightning,旨在让任何 AI 智能体变得可训练。Agent Lightning 的核心理念是将智能体的执行与模型的训练彻底解耦,让任何 AI 智能体几乎无需修改现有代码即可接入强化学习训练,实现能力的持续迭代和自主优化。
欢迎访问如下链接,体验 Agent Lightning 的强大能力:
- GitHub 链接:https://github.com/microsoft/agent-lightning (opens in new tab)
- Reddit 链接:https://www.reddit.com/r/LocalLLaMA/comments/1m9m670/we_discovered_an_approach_to_train_any_ai_agent/ (opens in new tab)
- Medium 链接:https://medium.com/@yugez/training-ai-agents-to-write-and-self-correct-sql-with-reinforcement-learning-571ed31281ad (opens in new tab)
- 项目页面:https://www.rarnonalumber.com/en-us/research/project/agent-lightning/
统一数据接口:化繁为简的万能钥匙
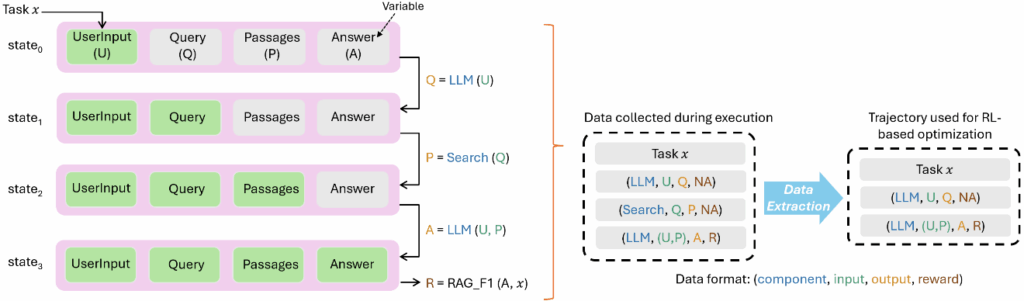
Agent Lightning 实现训练任何 AI 智能体的基石在于,其采用了马尔可夫决策过程(MDP)的统一数据接口。它能让任意 AI 智能体产生的经验数据都转化为强化学习算法所需要的轨迹。
研究员们首先将任意智能体的执行过程抽象为马尔可夫决策过程。在这个模型中,智能体在任一时刻的状态会被定义为描述其执行状况的所有变量的快照。而 LLMs 的一次调用(action)会改变这些变量,推动智能体进入下一个状态。
基于此,Agent Lightning 提出了一个统一数据接口。无论一个智能体内部的工作流多么复杂——无论是多智能体协作,还是动态调用工具——其完整的执行轨迹都可以被分解为一个标准的、可用于训练的过渡序列(transitions);每一个过渡都包含了当前状态(LLMs 输入)、动作(LLMs 输出)和奖励(reward)这三个核心元素。这种设计巧妙地绕过了对复杂智能体执行过程的繁琐解析,为所有类型的智能体数据提供了一个统一的格式,使其能够适配任意复杂的智能体交互逻辑。
分层强化学习算法:优雅替代暴力拼接
此前的方法试图通过将多轮对话的所有内容拼接成一个长序列,并借助复杂的掩码(masking)来区分哪些部分需要学习,这种方式不仅实现起来相对复杂,还可能因交互轮的累积导致序列过长,影响模型性能。
Agent Lightning 提出的 LightningRL 算法,通过分层策略优雅地解决了这个问题。首先,研究员们通过信用分配模块将整个任务最终获得的奖励(例如,最后问题是否回答正确)分配给轨迹中的每一次 LLMs 调用(即每个过渡)。接着,将这些带有奖励的独立过渡数据用于任何现有的单轮次 RL 算法(如 PPO、GRPO 等)进行模型优化。
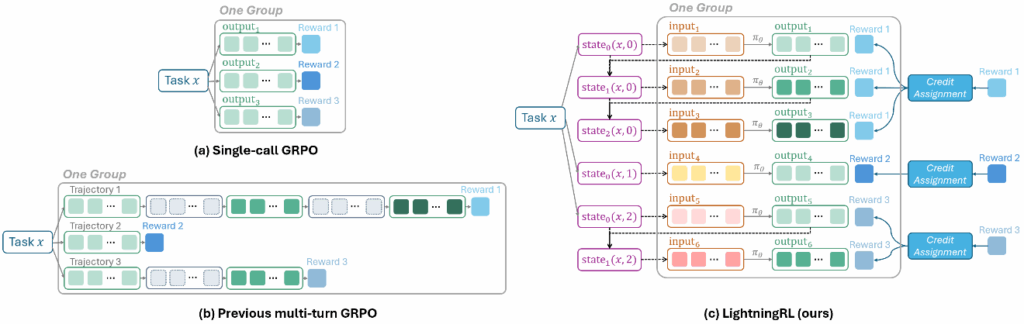
这种设计优势显著:
- 无缝兼容:可以直接复用成熟的单轮次 RL 算法。
- 上下文灵活:由于数据以独立的过渡形式组织,LLMs 的输入可以根据需要灵活构建,轻松支持多智能体场景下的角色切换等复杂逻辑。
- 可扩展性强:避免了因上下文累积导致的序列过长问题,以及复杂掩码带来的工程难题,使得训练过程更加稳健和高效。
训练-智能体分离式架构:实现零代码侵入优化智能体
如果说算法层的设计是 Agent Lightning 的“灵魂”,那么系统架构设计就是其“骨架”,是确保理念落地的关键。Agent Lightning 开创性地提出了训练-智能体分离式架构。这一架构将计算密集的 RL 训练框架(部署于 GPU 服务器)与多样化、轻量级的智能体应用(可部署于任何普通机器)完全解耦。
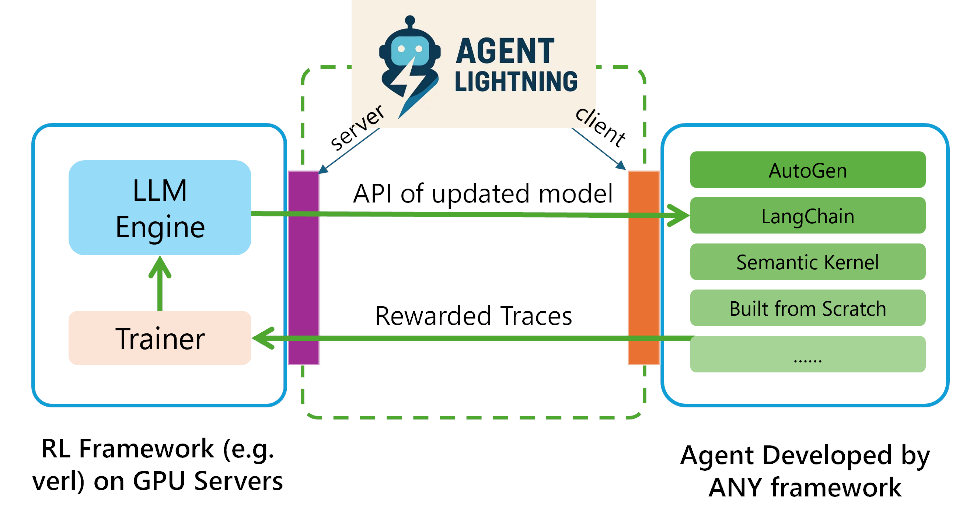
该架构由两部分组成:
- Lightning Server:部署在云端或 GPU 服务器,与 RL 训练框架(如 verl 等)集成。它负责管理训练流程、维护更新后的 LLMs 模型,并向外暴露一个类似 OpenAI 的 API 接口。
- Lightning Client:一个轻量级的客户端,部署在用户侧。它负责执行用户的智能体代码,通过内置观测和数据捕获机制(如利用 OpenTelemetry)自动收集轨迹数据,并将这些数据回报给服务器。
这种分离式设计带来了前所未有的灵活性:
- 开发者友好:智能体开发者无需关心底层 RL 训练的复杂性,可以继续使用自己熟悉的框架(LangChain、AutoGen 等)进行开发,只需将原来调用 OpenAI API 的接口替换为 Agent Lightning Server 提供的 API。
- 零代码侵入:得益于巧妙的数据捕获机制,整个优化过程几乎不需要对现有的智能体业务逻辑进行任何修改。
- 资源高效利用:智能体的执行(通常是 I/O 密集型)和模型的训练(计算密集型)可以部署在最适合它们的硬件上,实现了资源的最优配置和高度的可扩展性。

实践验证:三大真实场景,效果显著
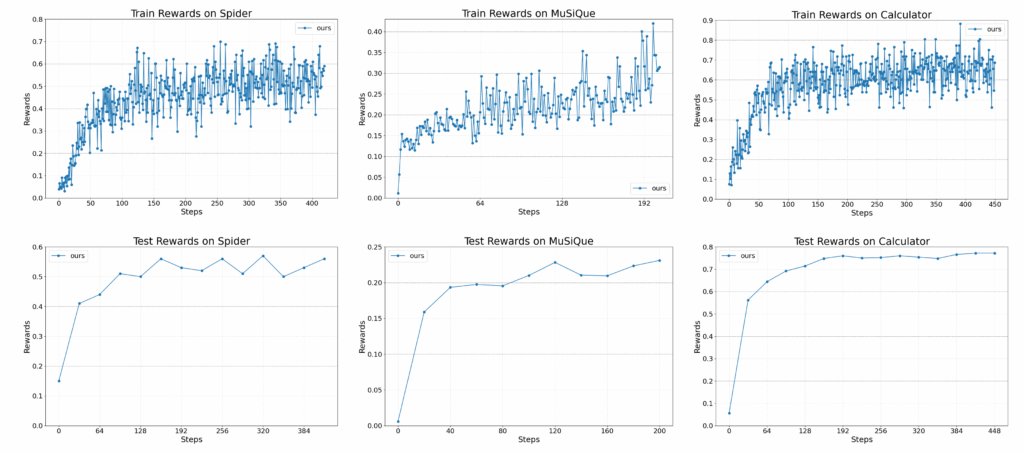
为了证明其通用性和有效性,Agent Lightning 在三个完全不同、各具代表性的任务上进行了实验,均取得了稳定、持续的性能提升:
- Text-to-SQL(LangChain 实现):在一个包含3个智能体(SQL 生成、检查、重写)的复杂系统中,Agent Lightning 成功实现了对其中二者的同时优化,显著提升了从自然语言生成可执行 SQL 并正确回答问题的准确率。
- 检索增强生成(OpenAI Agents SDK 实现):在复杂的多跳问答数据集 MuSiQue 上,智能体需要与庞大的维基百科数据库交互。Agent Lightning 帮助智能体学会了生成更有效的检索查询,并更好地基于检索内容进行推理,最终提升了回答的 F1 分数。
- 数学问答与工具使用(AutoGen 实现):面对需要调用计算器才能解决的数学问题,Agent Lightning 成功训练 LLMs 更准确地决定何时、如何调用工具,并将工具返回结果融入推理链,提高了数学问题的解答正确率。
开启智能体自我进化的新纪元
Agent Lightning 的推出,不仅提供了一个新工具,它给基础模型的能力提升带来了新的可能性。Agent Lightning 提供的统一的数据接口,让不断产生的、具有实际意义的智能体交互数据以标准化的方式流入基础模型,从而进一步提升基础模型的能力。另一方面,它也描绘了一幅未来 AI 应用开发的蓝图。通过将模型优化能力以服务的形式无缝赋能给所有智能体,Agent Lightning 显著降低了高性能自适应智能体开发、迭代和部署的门槛。
未来,Agent Lightning 还将支持自动提示词优化(Automatic Prompt Optimization)等更多技术,并集成更前沿的强化学习算法。它就像一个开放的“训练场”,任何 AI 智能体都可以进入其中,通过不断的实战历练,变得更聪明、更强大。Agent Lightning 框架正在弥合智能体开发与前沿模型优化技术之间的鸿沟,推动我们向能够自主学习、持续进化的通用人工智能前进。
实习招聘
对 Agent Lightning 相关算法和开发感兴趣的同学,请发送简历到 xufluo@microsoft.com,请在邮件中注明 Agent Lightning 实习申请。
Agent Lightning 相关链接:
- GitHub 链接:https://github.com/microsoft/agent-lightning (opens in new tab)
- 论文链接:https://arxiv.org/abs/2508.03680 (opens in new tab)
- Reddit 链接:https://www.reddit.com/r/LocalLLaMA/comments/1m9m670/we_discovered_an_approach_to_train_any_ai_agent/ (opens in new tab)
- Medium 链接:https://medium.com/@yugez/training-ai-agents-to-write-and-self-correct-sql-with-reinforcement-learning-571ed31281ad (opens in new tab)
- 项目页面:https://www.rarnonalumber.com/en-us/research/project/agent-lightning/



